Last week, I shared a tutorial on using PrivateGPT. It’s an AI tool to interact with documents.
Now, that’s fine for the limited use, but if you want something more than just interacting with a document, you need to explore other projects.
That’s when I came across a fascinating project called Ollama. It’s an open source project that lets you run various Large Language Models (LLM’s) locally.
While browsing through Reddit communities, I came across discussions that talk about running LLMs on Raspberry Pi.
I was curious to verify this ‘claim’ so I decided to run LLMs locally with Ollama on my Raspberry Pi 4.
Let me share my experiments with you in this brief article.
📋
This article assumes that you have the basic understanding of AI, LLMs and other related tools and jargon.
Installing Ollama on Raspberry Pi OS (and other Linux)
The installation process of Ollama is effortless. For installation on Linux, you have to fetch their official installation script and run it. That’s the official method described on their website.
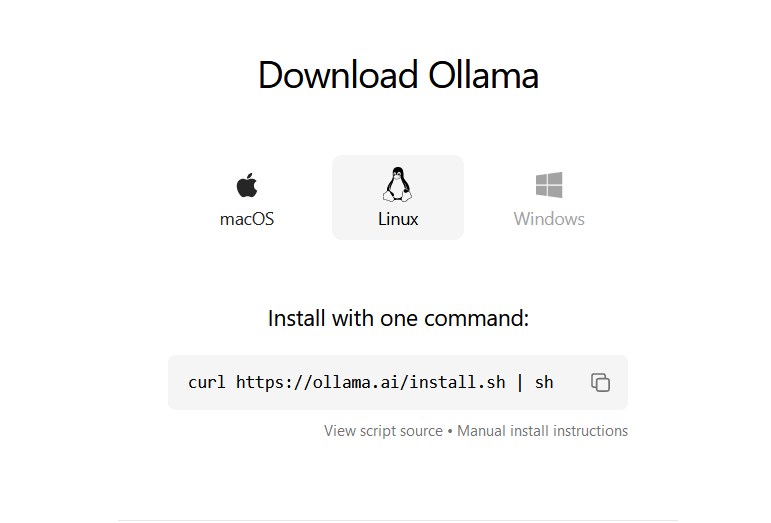
You can download it manually and read what it does. Or, if you are lazy like me, combine them both in a single command like this:
curl | sh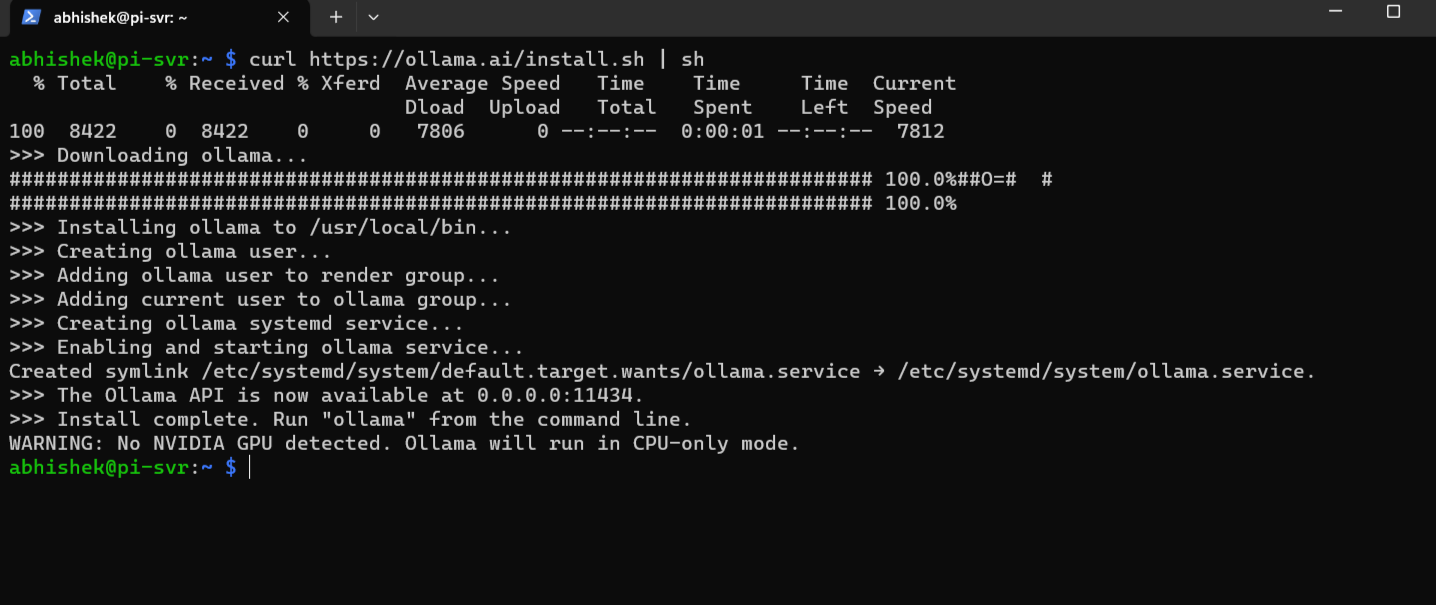
Exploring different LLMs
Once the installation is done, you are now all ready to run LLMs on Pi and start chatting with AI in no time.
In my experiment, I used tinyllama , phi and llava LLMs. But you may try different large language models that are available in Ollama’s library.
📋
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
TinyLlama
Let’s start with TinyLlama which is based on 1.1 billion parameters and is a perfect candidate for the first try.
To download and run TinyLlama, you need to type this command:
ollama run tinyllama
It will take a few seconds to download the language model and once it is downloaded, you can start chatting with it.
The question I pose to the AI is: “What is the use case of div tag in html?”
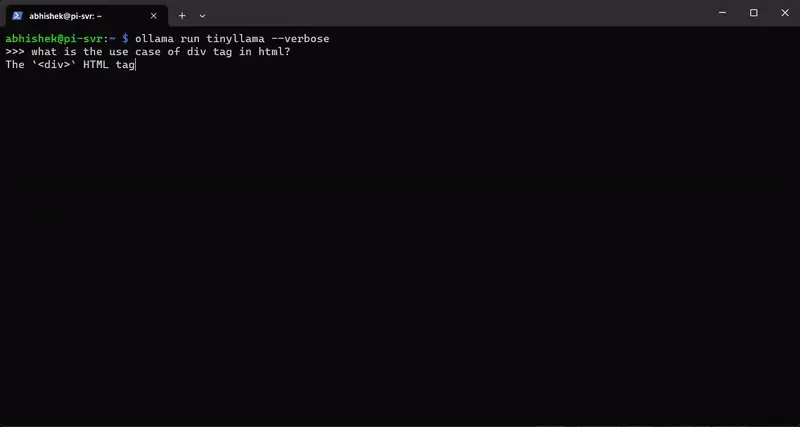
Here’s the full answer with the time it took to finish it:
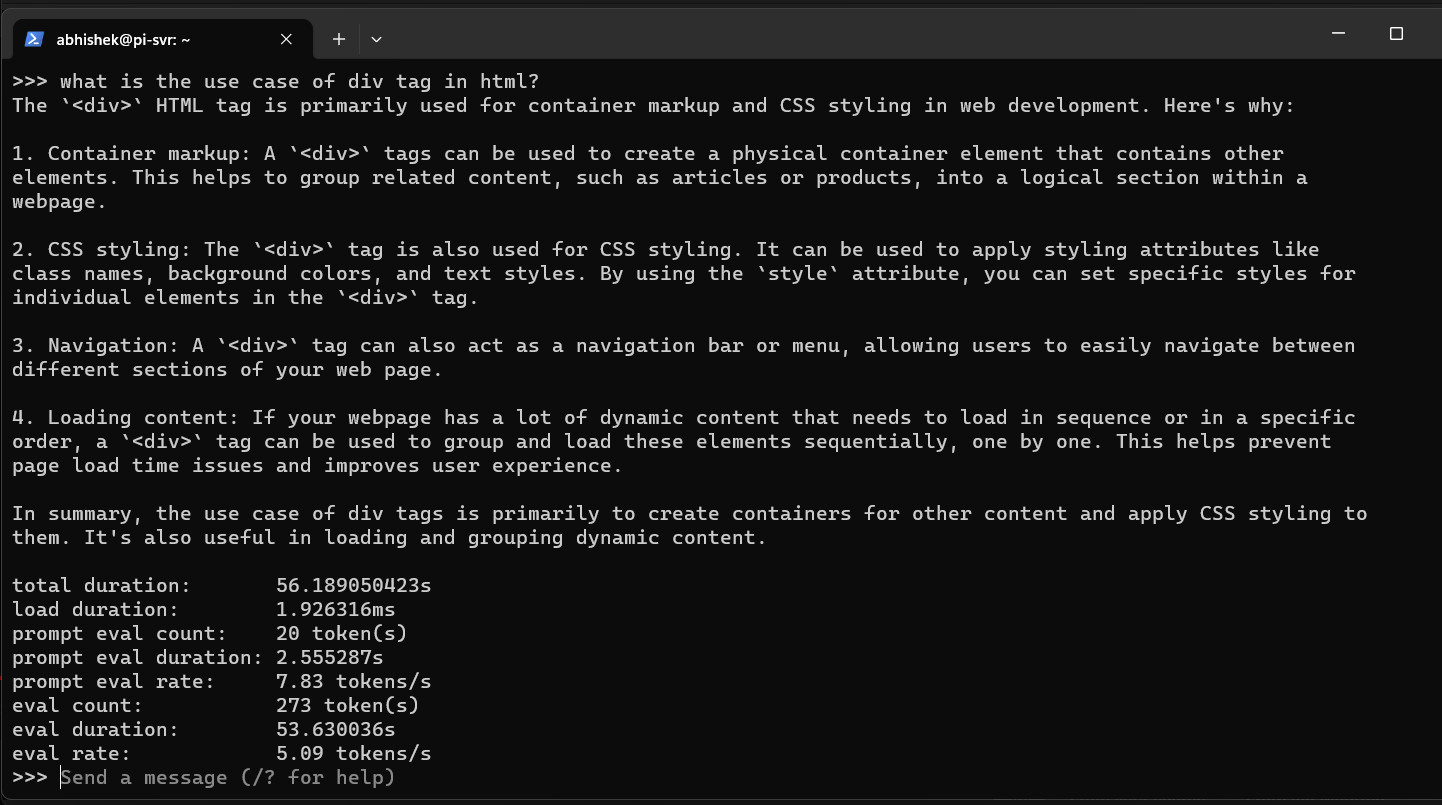
Well, well, well! Who would have guessed that AI would have worked this fast on a Raspberry Pi?
phi
Moving on to some bigger models like phi which is a 2.7B parameters-based language model. I think our Raspberry Pi can handle this as well.
To install and run this model, type this command:
ollama run phi
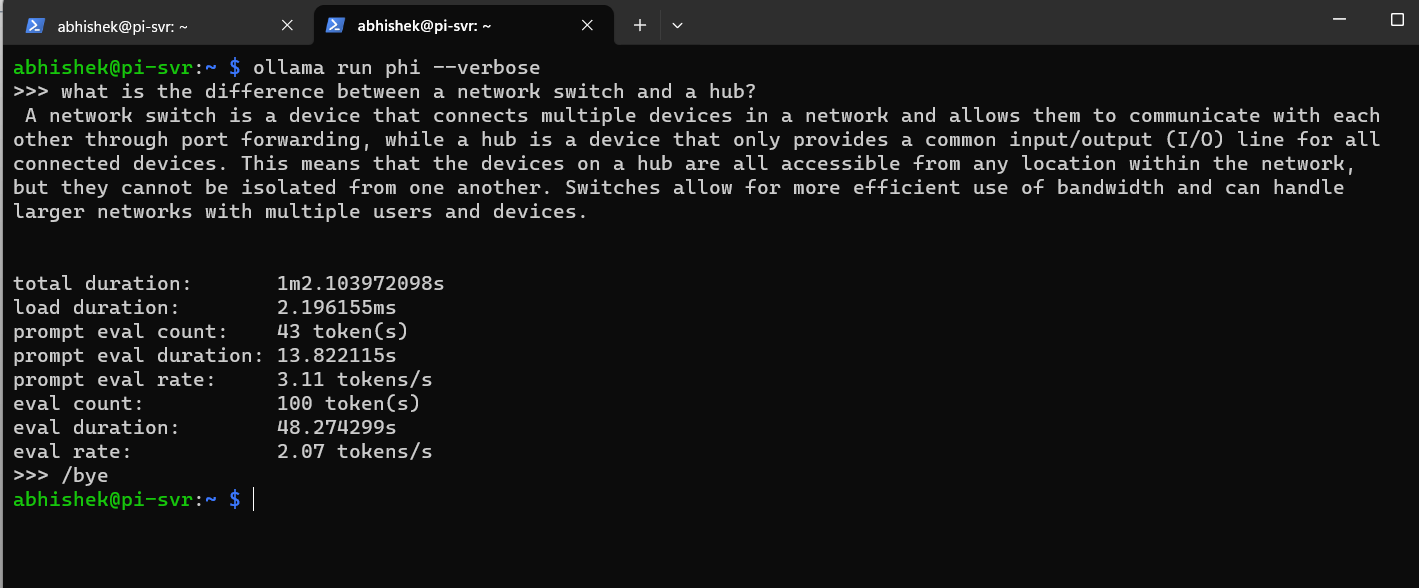
Try asking it some questions, like I did: “What is the difference between a network switch and a hub?”
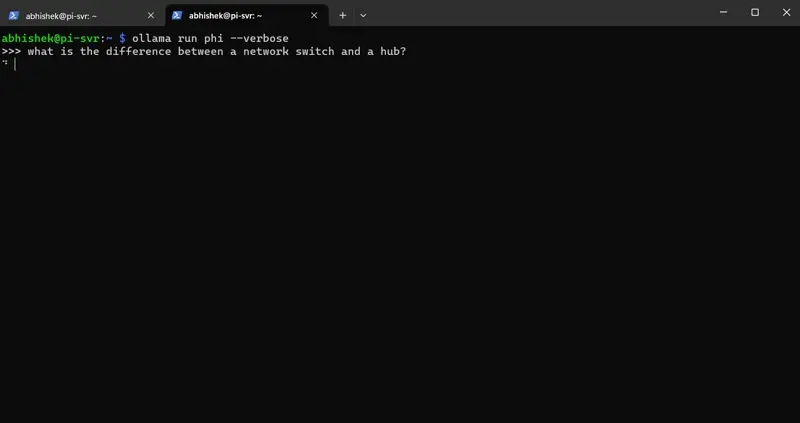
and here’s the complete answer from phi with other details:
llava
This is the biggest LLM that I test as it comes with 7B parameters. I ask it to describe an image instead of asking simple questions.
I am using a 4 GB model of Raspberry Pi 4 and I don’t think that it will work as well like the other language models did above.
But still, let’s test it. To install llava use this command:
ollama run llava
It will take some time to download this model, since it is quite big, somewhere close to 3.9 GB.

I am going to ask this model to describe an image of a cat that is stored in /media/hdd/shared/test.jpg directory.
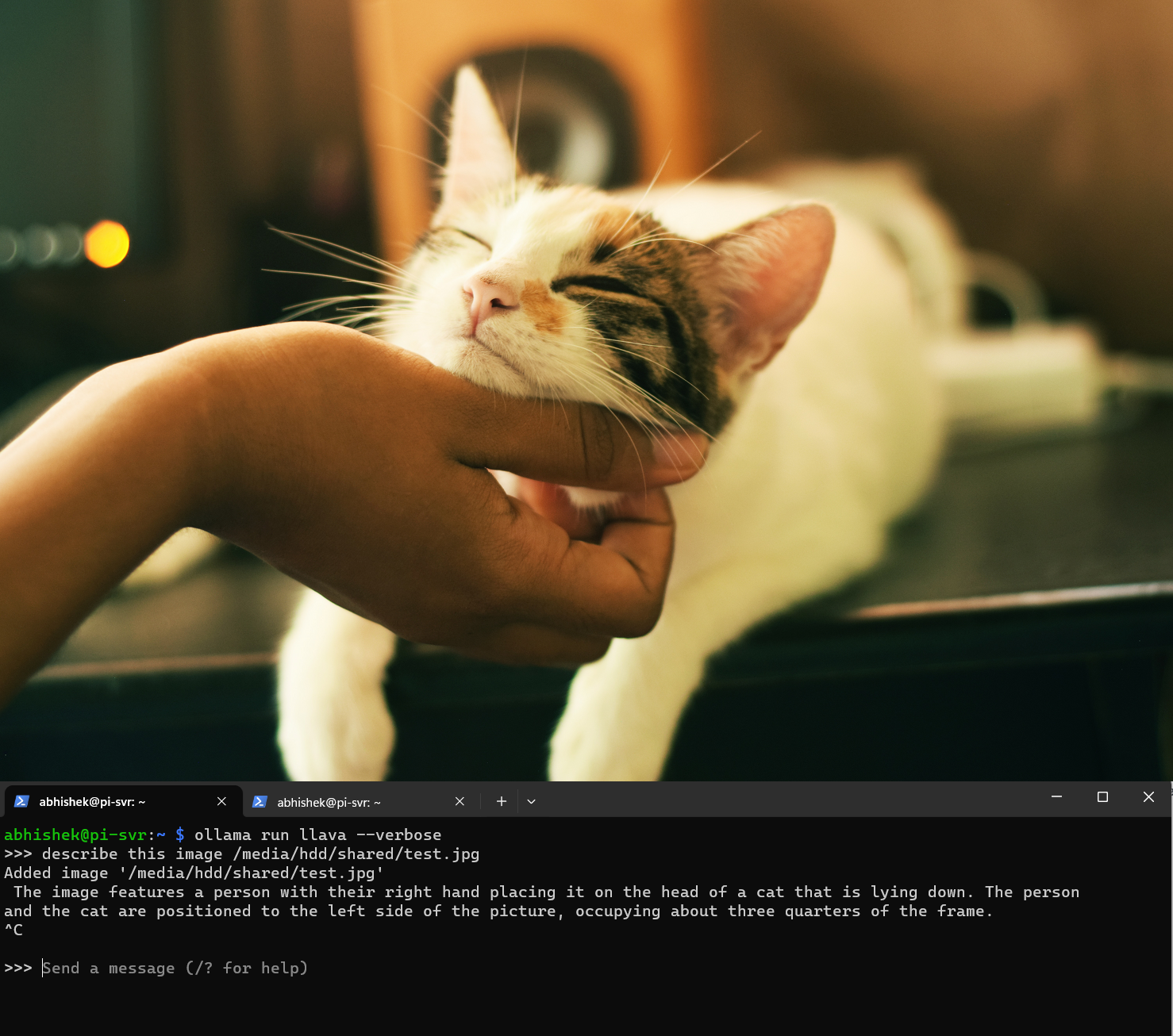
I had to terminate the process in the middle since it was taking too long to answer (more than 30 mins).
But you can see, the response is pretty accurate and if you have the latest Raspberry Pi 5 with 8 GB of RAM, you can run 7B parameter language models easily.
Conclusion
Combining the capabilities of the Raspberry Pi 5 with Ollama establishes a potent foundation for anyone keen on running open-source LLMs locally.
Whether you’re a developer striving to push the boundaries of compact computing or an enthusiast eager to explore the realm of language processing, this setup presents a myriad of opportunities.
Of course, you can use Ollama on regular Linux distros as well. We’ve a tutorial on that if you are interested.
Running AI Locally Using Ollama on Ubuntu Linux
Running AI locally on Linux because open source empowers us to do so.

Do let me know your thoughts and experience with Ollama in the comment section.