


Are you looking to showcase your brand in front of the gaming industry’s top leaders? Learn more about GamesBeat Summit sponsorship opportunities here.
Nvidia is introducing Chat with RTX to create personalized local AI chatbots on Windows AI PCs.
It’s the latest attempt by Nvidia to turn AI on its graphics processing units (GPUs) into a mainstream tool used by everyone.
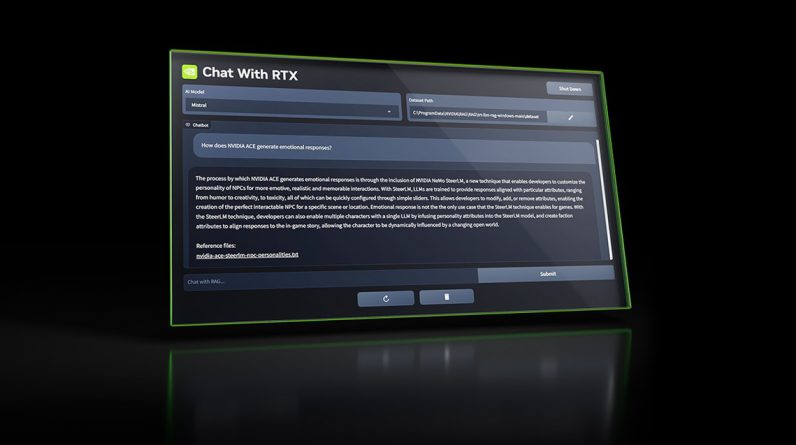
The new offering, Chat with RTX, allows users to harness the power of personalized generative AI directly on their local devices, showcasing the potential of retrieval-augmented generation (RAG) and TensorRT-LLM software. At the same time, it doesn’t burn up a lot of data center computing and it helps with local privacy so that users don’t have to worry about their AI chats.
Chatbots have become an integral part of daily interactions for millions globally, typically relying on cloud servers with Nvidia GPUs. However, the Chat with RTX tech demo shifts this paradigm by enabling users to enjoy the benefits of generative AI locally, using the processing power of Nvidia GeForce RTX 30 Series GPUs or higher with a minimum of 8GB of video random access memory (VRAM).
GB Event
GamesBeat Summit Call for Speakers
We’re thrilled to open our call for speakers to our flagship event, GamesBeat Summit 2024 hosted in Los Angeles, where we will explore the theme of “Resilience and Adaption”.
Apply to speak here
Personalized AI experience
Nvidia said that Chat with RTX is more than a mere chatbot; it’s a personalized AI companion that users can customize with their own content. By leveraging the capabilities of local GeForce-powered Windows PCs, users can accelerate their experience and enjoy the benefits of generative AI with unprecedented speed and privacy, the company said.
The tool leverages RAG, TensorRT-LLM software, and Nvidia RTX acceleration to facilitate quick, contextually relevant answers based on local datasets. Users can connect the application to local files on their PCs, turning them into a dataset for open-source large language models like Mistral or Llama 2.
Rather than sifting through various files, users can type natural language queries, such as asking about a restaurant recommendation or any personalized information, and Chat with RTX will swiftly scan and provide the answer with context. The application supports a variety of file formats, including .txt, .pdf, .doc/.docx, and .xml, making it versatile and user-friendly.
Integration of multimedia content
 Chat with RTX works on an Nvidia AI PC.
Chat with RTX works on an Nvidia AI PC.
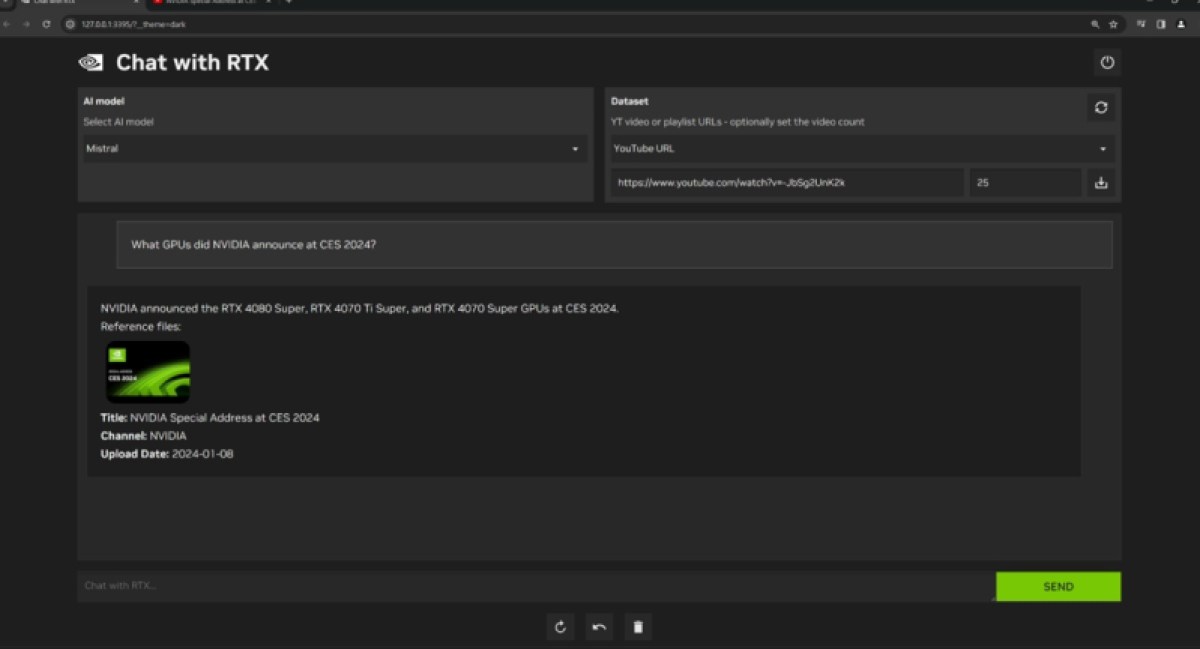
What sets Chat with RTX apart is its ability to include information from multimedia sources, particularly YouTube videos and playlists, Nvidia said.
Users can integrate knowledge from video content into their chatbot, enabling contextual queries. For instance, users can seek travel recommendations based on their favorite influencer’s videos or obtain quick tutorials and how-tos from educational resources.
The application’s local processing capabilities ensure fast results, and importantly, user data stays on the device. By eliminating the need for cloud-based services, Chat with RTX allows users to handle sensitive data without sharing it with third parties or requiring an internet connection.
System requirements and future possibilities
To experience Chat with RTX, users need a GeForce RTX 30 Series GPU or higher with a minimum of 8GB of VRAM, along with Windows 10 or 11 and the latest Nvidia GPU drivers.
Developers can explore the potential of accelerating large language models (LLMs) with RTX GPUs by referring to the TensorRT-LLM RAG developer reference project available on GitHub. Nvidia encourages developers to participate in the Generative AI on Nvidia RTX developer contest, running until February 23, offering opportunities to win prizes such as a GeForce RTX 4090 GPU and a full, in-person conference pass to Nvidia GTC.
The Chat with RTX tech demo is now available for free download.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.






