Reviewed and fact-checked by Sayantoni Das
Search algorithms are algorithms designed to search for or retrieve elements from a data structure, where they are stored. They are essential to access desired elements in a data structure and retrieve them when a need arises. A vital aspect of search algorithms is Path Finding, which is used to find paths that can be taken to traverse from one point to another, by finding the most optimum route.
In this tutorial titled ‘A* Algorithm – An Introduction To The powerful search algorithm’, you will be dealing with the A* algorithm, which is a search algorithm that finds the shortest path between two points.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
What is an A* Algorithm?
It is a searching algorithm that is used to find the shortest path between an initial and a final point.
It is a handy algorithm that is often used for map traversal to find the shortest path to be taken. A* was initially designed as a graph traversal problem, to help build a robot that can find its own course. It still remains a widely popular algorithm for graph traversal.
It searches for shorter paths first, thus making it an optimal and complete algorithm. An optimal algorithm will find the least cost outcome for a problem, while a complete algorithm finds all the possible outcomes of a problem.
Another aspect that makes A* so powerful is the use of weighted graphs in its implementation. A weighted graph uses numbers to represent the cost of taking each path or course of action. This means that the algorithms can take the path with the least cost, and find the best route in terms of distance and time.
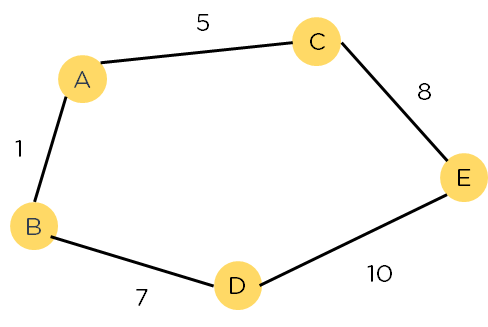
Figure 1: Weighted Graph
A major drawback of the algorithm is its space and time complexity. It takes a large amount of space to store all possible paths and a lot of time to find them.
[Related reading: Top 45 Data Structure Interview Questions and Answers for 2022]
Applications of A* Algorithm
The A* algorithm is widely used in various domains for pathfinding and optimization problems. It has applications in robotics, video games, route planning, logistics, and artificial intelligence. In robotics, A* helps robots navigate obstacles and find optimal paths. In video games, it enables NPCs to navigate game environments intelligently. Route planning applications use A* to find the shortest or fastest routes between locations. Logistics industries utilize A* for vehicle routing and scheduling. A* is also employed in AI systems, such as natural language processing and machine learning, to optimize decision-making processes. Its versatility and efficiency make it a valuable algorithm in many real-world scenarios.
Why A* Search Algorithm?
A* Search Algorithm is a simple and efficient search algorithm that can be used to find the optimal path between two nodes in a graph. It will be used for the shortest path finding. It is an extension of Dijkstra’s shortest path algorithm (Dijkstra’s Algorithm). The extension here is that, instead of using a priority queue to store all the elements, we use heaps (binary trees) to store them. The A* Search Algorithm also uses a heuristic function that provides additional information regarding how far away from the goal node we are. This function is used in conjunction with the f-heap data structure in order to make searching more efficient.
Let us now look at a brief explanation of the A* algorithm.
Explanation
In the event that we have a grid with many obstacles and we want to get somewhere as rapidly as possible, the A* Search Algorithms are our savior. From a given starting cell, we can get to the target cell as quickly as possible. It is the sum of two variables’ values that determines the node it picks at any point in time.
At each step, it picks the node with the smallest value of ‘f’ (the sum of ‘g’ and ‘h’) and processes that node/cell. ‘g’ and ‘h’ is defined as simply as possible below:
- ‘g’ is the distance it takes to get to a certain square on the grid from the starting point, following the path we generated to get there.
- ‘h’ is the heuristic, which is the estimation of the distance it takes to get to the finish line from that square on the grid.
Heuristics are basically educated guesses. It is crucial to understand that we do not know the distance to the finish point until we find the route since there are so many things that might get in the way (e.g., walls, water, etc.). In the coming sections, we will dive deeper into how to calculate the heuristics.
Let us now look at the detailed algorithm of A*.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Algorithm
Initial condition – we create two lists – Open List and Closed List.
Now, the following steps need to be implemented –
- The open list must be initialized.
- Put the starting node on the open list (leave its f at zero). Initialize the closed list.
- Follow the steps until the open list is non-empty:
- Find the node with the least f on the open list and name it “q”.
- Remove Q from the open list.
- Produce q’s eight descendants and set q as their parent.
- For every descendant:
i) If finding a successor is the goal, cease looking
ii)Else, calculate g and h for the successor.
successor.g = q.g + the calculated distance between the successor and the q.
successor.h = the calculated distance between the successor and the goal. We will cover three heuristics to do this: the Diagonal, the Euclidean, and the Manhattan heuristics.
successor.f = successor.g plus successor.h
iii) Skip this successor if a node in the OPEN list with the same location as it but a lower f value than the successor is present.
iv) Skip the successor if there is a node in the CLOSED list with the same position as the successor but a lower f value; otherwise, add the node to the open list end (for loop).
- Push Q into the closed list and end the while loop.
We will now discuss how to calculate the Heuristics for the nodes.
Master Tools You Need For Becoming an AI Engineer
AI Engineer Master’s ProgramExplore Program![]()
Heuristics
We can easily calculate g, but how do we actually calculate h?
There are two methods that we can use to calculate the value of h:
1. Determine h’s exact value (which is certainly time-consuming).
(or)
2. Utilize various techniques to approximate the value of h. (less time-consuming).
Let us discuss both methods.
Exact Heuristics
Although we can obtain exact values of h, doing so usually takes a very long time.
The ways to determine h’s precise value are listed below.
1. Before using the A* Search Algorithm, pre-calculate the distance between every pair of cells.
2. Using the distance formula/Euclidean Distance, we may directly determine the precise value of h in the absence of blocked cells or obstructions.
Let us look at how to calculate Approximation Heuristics.
Future-Proof Your AI/ML Career: Top Dos and Don’ts
Free Webinar | 5 Dec, Tuesday | 7 PM ISTRegister Now![]()
Approximation Heuristics
To determine h, there are typically three approximation heuristics:
1. Manhattan Distance
The Manhattan Distance is the total of the absolute values of the discrepancies between the x and y coordinates of the current and the goal cells.
The formula is summarized below –
h = abs (curr_cell.x – goal.x) +
abs (curr_cell.y – goal.y)
We must use this heuristic method when we are only permitted to move in four directions – top, left, right, and bottom.
Let us now take a look at the Diagonal Distance method to calculate the heuristic.
2. Diagonal Distance
It is nothing more than the greatest absolute value of differences between the x and y coordinates of the current cell and the goal cell.
This is summarized below in the following formula –
dx = abs(curr_cell.x – goal.x)
dy = abs(curr_cell.y – goal.y)
h = D * (dx + dy) + (D2 – 2 * D) * min(dx, dy)
where D is the length of every node (default = 1) and D2 is the diagonal
We use this heuristic method when we are permitted to move only in eight directions, like the King’s moves in Chess.
Let us now take a look at the Euclidean Distance method to calculate the heuristic.
3. Euclidean Distance
The Euclidean Distance is the distance between the goal cell and the current cell using the distance formula:
h = sqrt ( (curr_cell.x – goal.x)^2 +
(curr_cell.y – goal.y)^2 )
We use this heuristic method when we are permitted to move in any direction of our choice.
Want To Become an AI Engineer? Look No Further!
AI Engineer Master’s ProgramExplore Program![]()
The Basic Concept of A* Algorithm
A heuristic algorithm sacrifices optimality, with precision and accuracy for speed, to solve problems faster and more efficiently.
All graphs have different nodes or points which the algorithm has to take, to reach the final node. The paths between these nodes all have a numerical value, which is considered as the weight of the path. The total of all paths transverse gives you the cost of that route.
Initially, the Algorithm calculates the cost to all its immediate neighboring nodes,n, and chooses the one incurring the least cost. This process repeats until no new nodes can be chosen and all paths have been traversed. Then, you should consider the best path among them. If f(n) represents the final cost, then it can be denoted as :
f(n) = g(n) + h(n), where :
g(n) = cost of traversing from one node to another. This will vary from node to node
h(n) = heuristic approximation of the node’s value. This is not a real value but an approximation cost
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
How Does the A* Algorithm Work?
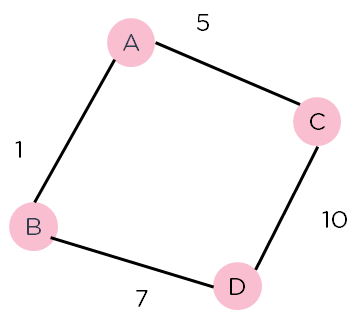
Figure 2: Weighted Graph 2
Consider the weighted graph depicted above, which contains nodes and the distance between them. Let’s say you start from A and have to go to D.
Now, since the start is at the source A, which will have some initial heuristic value. Hence, the results are
f(A) = g(A) + h(A)
f(A) = 0 + 6 = 6
Next, take the path to other neighbouring vertices :
f(A-B) = 1 + 4
f(A-C) = 5 + 2
Now take the path to the destination from these nodes, and calculate the weights :
f(A-B-D) = (1+ 7) + 0
f(A-C-D) = (5 + 10) + 0
It is clear that node B gives you the best path, so that is the node you need to take to reach the destination.
Pseudocode of A* Algorithm
The text below represents the pseudocode of the Algorithm. It can be used to implement the algorithm in any programming language and is the basic logic behind the Algorithm.
- Make an open list containing starting node
- If it reaches the destination node :
- Make a closed empty list
- If it does not reach the destination node, then consider a node with the lowest f-score in the open list
We are finished
Put the current node in the list and check its neighbors
- For each neighbor of the current node :
- If the neighbor has a lower g value than the current node and is in the closed list:
Replace neighbor with this new node as the neighbor’s parent
- Else If (current g is lower and neighbor is in the open list):
Replace neighbor with the lower g value and change the neighbor’s parent to the current node.
- Else If the neighbor is not in both lists:
Add it to the open list and set its g
How to Implement the A* Algorithm in Python?
Consider the graph shown below. The nodes are represented in pink circles, and the weights of the paths along the nodes are given. The numbers above the nodes represent the heuristic value of the nodes.
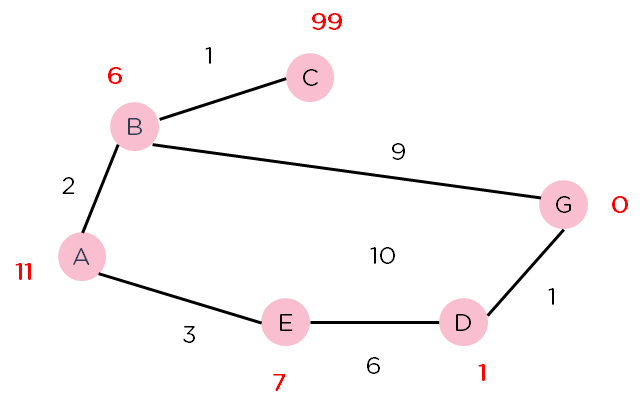
Figure 3: Weighted graph for A* Algorithm
You start by creating a class for the algorithm. Now, describe the open and closed lists. Here, you are using sets and two dictionaries – one to store the distance from the starting node, and another for parent nodes. And initialize them to 0, and the start node.

Figure 4: Initializing important parameters
Now, find the neighboring node with the lowest f(n) value. You must also code for the condition of reaching the destination node. If this is not the case, put the current node in the open list if it’s not already on it, and set its parent nodes.
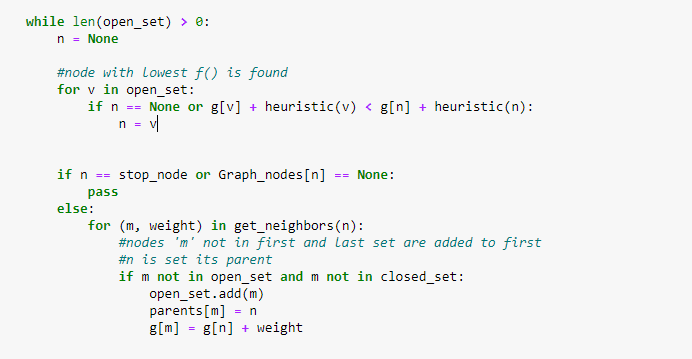
Figure 5: Adding nodes to open list and setting parents of nodes
If the neighbor has a lower g value than the current node and is in the closed list, replace it with this new node as the neighbor’s parent.

Figure 6: Checking distances and updating the g values
If the current g is lower than the previous g, and its neighbor is in the open list, replace it with the lower g value and change the neighbor’s parent to the current node.
If the neighbor is not in both lists, add it to the open list and set its g value.
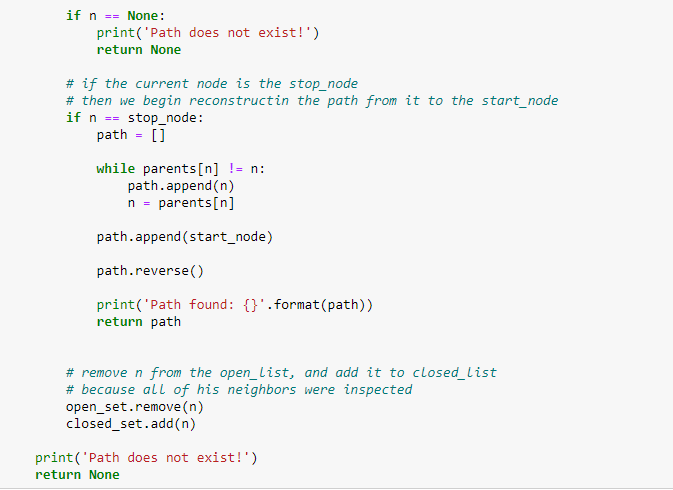
Figure 7: Checking distances, updating the g values, and adding parents
Now, define a function to return neighbors and their distances.

Figure 8: Defining neighbors
Also, create a function to check the heuristic values.
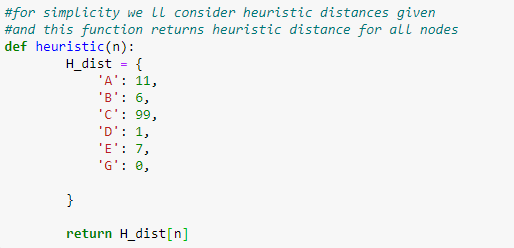
Figure 9: Defining a function to return heuristic values
Let’s describe our graph and call the A star function.
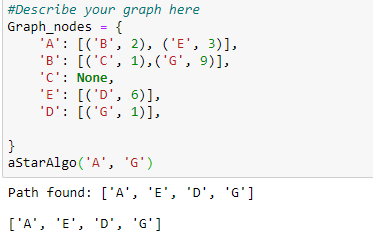
Figure 10: Calling A* function
The algorithm traverses through the graph and finds the path with the least cost
which is through E => D => G.
Advantages of A* Algorithm
The A* algorithm offers several advantages.
- Firstly, it guarantees finding the optimal path when used with appropriate heuristics.
- Secondly, it is efficient and can handle large search spaces by effectively pruning unpromising paths.
- Thirdly, it can be easily tailored to accommodate different problem domains and heuristics.
- Fourthly, A* is flexible and adaptable to varying terrain costs or constraints. Additionally, it is widely implemented and has a vast amount of resources and support available.
Overall, the advantages of A* make it a popular choice for solving pathfinding and optimization problems.
Disadvantages of A* Algorithm
While the A* algorithm has numerous advantages, it also has some limitations.
- One disadvantage is that A* can be computationally expensive in certain scenarios, especially when the search space is extensive and the number of possible paths is large.
- The algorithm may consume significant memory and processing resources.
- Another limitation is that A* heavily relies on the quality of the heuristic function. If the heuristic is poorly designed or does not accurately estimate the distance to the goal, the algorithm’s performance and optimality may be compromised.
- Additionally, A* may struggle with certain types of graphs or search spaces that exhibit irregular or unpredictable structures.
What if the search space in A* Algorithm is not a grid and is a graph?
The A* algorithm can be applied to non-grid search spaces that are represented as graphs. In this case, the nodes in the graph represent states or locations, and the edges represent the connections or transitions between them. The key difference lies in the definition of neighbors for each node, which is determined by the edges in the graph rather than the adjacent cells in a grid. A* can still be used to find the optimal path in such graph-based search spaces by appropriately defining the heuristic function and implementing the necessary data structures and algorithms to traverse the graph.
Examples of A* Algorithm
A* has been successfully applied in numerous real-world scenarios. For instance, in robotic path planning, A* helps robots navigate through dynamic environments while avoiding obstacles. In game development, A* is used to create intelligent enemy AI that can chase and follow the player efficiently. In logistics and transportation, A* assists in finding the optimal routes for delivery vehicles, minimizing time and cost. Additionally, A* has applications in network routing, such as finding the shortest path in a computer network. These examples highlight the versatility and practicality of A* algorithm concepts and implementations in various domains.
Conclusion
In this tutorial, an introduction to the powerful search algorithm’, you learned about everything about the algorithm and saw the basic concept behind it. You then looked into the working of the algorithm, and the pseudocode for A*. You finally saw how to implement the algorithm in Python.
Simplilearn’s Post Graduate Program in AI & ML is designed to help learners decode the mystery of artificial intelligence and its business applications. The course provides an overview of AI concepts and workflows, machine learning and deep learning, and performance metrics.
Do you have any doubts or questions for us on this topic? Mention them in the comments section of this tutorial, and we’ll have our experts answer them for you at the earliest!
Choose the Right Program
Supercharge your career in AI and ML with Simplilearn’s comprehensive courses. Gain the skills and knowledge to transform industries and unleash your true potential. Enroll now and unlock limitless possibilities!
| Program Name | AI Engineer | Post Graduate Program In Artificial Intelligence | Post Graduate Program In Artificial Intelligence |
| Geo | All Geos | All Geos | IN/ROW |
| University | Simplilearn | Purdue | Caltech |
| Course Duration | 11 Months | 11 Months | 11 Months |
| Coding Experience Required | Basic | Basic | No |
| Skills You Will Learn | 10+ skills including data structure, data manipulation, NumPy, Scikit-Learn, Tableau and more. | 16+ skills including chatbots, NLP, Python, Keras and more. |
8+ skills including Supervised & Unsupervised Learning Deep Learning Data Visualization, and more. |
| Additional Benefits | Get access to exclusive Hackathons, Masterclasses and Ask-Me-Anything sessions by IBM Applied learning via 3 Capstone and 12 Industry-relevant Projects |
Purdue Alumni Association Membership Free IIMJobs Pro-Membership of 6 months Resume Building Assistance | Upto 14 CEU Credits Caltech CTME Circle Membership |
| Cost | $$ | $$$$ | $$$$ |
| Explore Program | Explore Program | Explore Program |
FAQs
1. Why is it called A* algorithm?
The A* algorithm gets its name from two key features. The “A” stands for “Admissible” as it uses an admissible heuristic to estimate costs. The “*” signifies that it combines actual and estimated costs to make informed decisions during the search process.
2. What are the properties of A* algorithm?
The A* algorithm possesses properties of completeness, optimality, and efficiency. It guarantees finding a solution if one exists (completeness), finds the optimal path with the lowest cost (optimality), and efficiently explores fewer nodes by utilizing heuristics (efficiency).
3. What are the main components of A* algorithm?
The main components of the A* algorithm include an open list to track nodes to explore, a closed list to store evaluated nodes, a heuristic function to estimate costs, a cost function to assign costs to actions, and a priority queue to determine the order of node expansion based on estimated costs.