


Machine learning (ML) is one of the most talked-about topics in the world of technology. By now you must have heard about it. If you already know the basics of machine learning and know-how and where it is being used, this article will complement that knowledge. If you are new to machine learning, the basics covered in this tutorial will get you up to speed.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
Life Without Machine Learning
First thing first, let us begin this introduction to machine learning tutorial by looking at how life was before machine learning came into existence, and all the differences it has made so far!
Someone who doesn’t know anything about machine learning basics or Artificial Intelligence (AI) may only think of robots or machines, as sci-movies portray it. But most people are unaware of how common machine learning basics are used in our daily lives. Some examples include:
Google Search
People generally turn to search engines, such as Google, for a wide range of information and answers. The search engine collects all of the information based on your search query and presents the results that are most relevant. Without Google, the task would be tedious, as you would have to go through tens or hundreds of books and articles.
Voice and Facial Recognition
At one point, facial recognition was only a concept shown in movies. But machine learning has made it possible and now many are using this feature for your benefit. For instance, Facebook automatically recognizes the people in a photo and tags them for you, saving a lot of time. Without machine learning, Siri, Cortana, or Iris would not be able to answer your questions.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Machine Learning Basics – Use of Machine Learning in Daily Life
Virtual Reality in the World of Gaming
PS4 and Xbox have introduced virtual reality glasses that bring a whole new level of detail into gaming. Every time your head moves in the real world, it replicates the movement in the virtual world, providing an excellent gaming experience.
Machine learning also plays a role in gesture control, and tracks body movement and makes a corresponding movement in the game.
Finally, in FIFA games, your opponent tends to adapt based on the kind of strategy or gameplay you follow, all thanks to machine learning.
Online Shopping
Next up in the introduction to machine learning tutorial comes a very exciting point, that is, online shopping! People who shop on Amazon generally notice a lot of product suggestions. If you buy a formal shirt, Amazon suggests formal shoes, ties, blazers, and apparel that go with what you buy. Machine learning is what powers that recommendation system.
Machine learning also plays a role in customer segmentation, a crucial aspect of business success for all e-commerce platforms. Machine learning helps e-commerce platforms differentiate between customers based on what they buy, how frequently they buy, and their reviews. This helps companies ensure that their customers are taken care of and that their needs are being fulfilled.
Commuting (Uber)
You probably use Uber often to get to different places on time. Uber uses machine learning in several ways, such as:
- Suggesting drop-off and pick-up points: Once you have traveled with Uber, you’ll see that the app suggests other places you might want to go, based on your previous journeys.
- Uber Share: When you’re taking a shared ride, the app makes sure that the car you get is shared with customers traveling the same route you take during your commute. The app uses machine learning to sort through various factors, such as distance, traffic, and ratings before vehicle allocation.
Now that you know the uses of machine learning in daily life, let’s learn about the machine learning basics in the next section of our introduction to machine learning tutorial.
What is Machine Learning?

Machine learning is an application of AI that provides systems the ability to learn on their own and improve from experiences without being programmed externally. If your computer had machine learning, it might be able to play difficult parts of a game or solve a complicated mathematical equation for you.
How Machine Learning Works
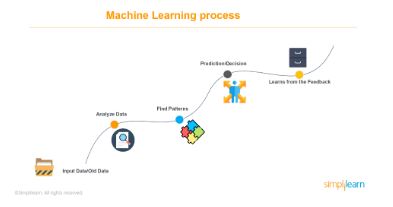
Consider a system with input data that contains photos of various kinds of fruits. You want the system to group the data according to the different types of fruits.
First, the system will analyze the input data. Next, it tries to find patterns, like shapes, size, and color. Based on these patterns, the system will try to predict the different types of fruit and segregate them. Finally, it keeps track of all the decisions it made during the process to ensure it is learning. The next time you ask the same system to predict and segregate the different types of fruits, it won’t have to go through the entire process again. That’s how machine learning works.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Machine Learning Basics – Types of Machine Learning
When talking about machine learning basics, you must know that it is comprised of three different types:
- Supervised machine learning: You supervise the machine while training it to work on its own. This requires labeled training data
- Unsupervised learning: There is training data, but it won’t be labeled
- Reinforcement learning: The system learns on its own
Supervised Learning
To understand how supervised learning works, look at the example below, where you have to train a model or system to recognize an apple.

First, you have to provide a data set that contains pictures of a kind of fruit, e.g., apples.
Then, provide another data set that lets the model know that these are pictures of apples. This completes the training phase.
Next, provide a new set of data that only contains pictures of apples. At this point, the system can recognize what the fruit it is and will remember it.
That’s how supervised learning works. You are training the model to perform a specific operation on its own. This kind of model is often used in filtering spam mail from your email accounts.
Unsupervised Learning

Consider a cluttered dataset: a collection of pictures of different fruit. You feed this data to the model, and the model analyzes it to recognize any patterns. In the end, the machine categorizes the photos into three types, as shown in the image, based on their similarities. Flipkart uses this model to find and recommend products that are well suited for you.
Reinforcement Learning
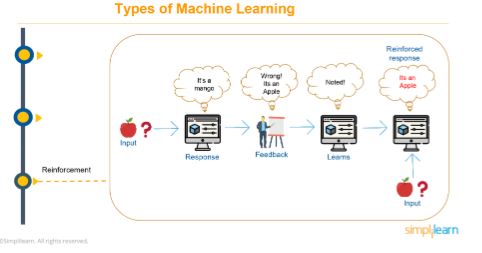
You provide a machine with a data set and ask it to identify a particular kind of fruit (in this case, an apple). The machine tells you that it’s mango, but that’s the wrong answer. As feedback, you tell the system that it’s wrong; it’s not a mango, it’s an apple. The machine then learns from the feedback and keeps that in mind. The next time you ask the same question, the system gives you the right answer; it is able to tell you that it’s an apple. That is a reinforced response.
That’s how reinforcement learning works; the system learns from its mistakes and experiences. This model is used in games like Prince of Persia, Assassin’s Creed, and FIFA, wherein the level of difficulty increases as you get better with the games.
Comparison Between Supervised and Unsupervised Learning
Supervised and unsupervised learning differ in several ways:
First, the data used in supervised learning is labeled. In the examples shown above, you provide the system with a photo of an apple and let the system know that this is an apple. That is called labeled data. The system learns from the labeled data and makes future predictions. On the other hand, unsupervised learning does not require any labeled data because its job is to look for patterns in the input data and organize it.
Second, you get feedback in the case of supervised learning. That is, once you receive the output, the system remembers it and uses it for the next operation. That does not happen with unsupervised learning.
Lastly, supervised learning is mostly used to predict data, whereas unsupervised learning is used to find hidden patterns or structures in data.
How do you Choose the Right Machine Learning Solution to Use?
This is a question that you need to answer before building a machine learning model.
Selecting the right kind of solution for your model is essential to avoid losing a lot of time, energy, and processing costs.
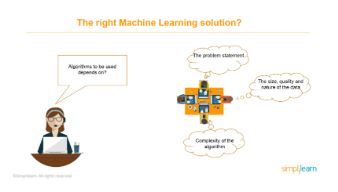
The following are factors that will help you select the right kind of machine learning solution based on supervised, unsupervised, and reinforcement learning:
- Imagine that you’d like to predict the future stock market prices. If you are new to machine learning, you would have trouble figuring out the right solution. But with time and practice, you will begin to understand that for a problem statement like this, solution-based supervised learning will work the best for obvious reasons.
- The size, quality, and nature of the data are also essential factors. If the data is cluttered, you will choose unsupervised. If the data set is extensive and categorical, choose supervised learning solutions.
- Finally, you should choose a solution based on the complexity of the algorithm. As for the problem statement where you predict stock market prices, using reinforcement learning can be a solution, although that would be difficult and time-consuming, unlike supervised learning.
Machine Learning Basics Algorithms
Algorithms are not types of machine learning. In the most straightforward language, they are methods of solving a particular problem.

Classification
The first method is classification, and it falls under supervised learning. Classification is used when the output you are looking for is a “yes” or “no,” or in the form of “a” or “b” or “true” or “false.”
For instance, if a shopkeeper wants to predict that a particular customer will come back to his shop or not, he will use a classification algorithm. Examples of classification algorithms include:
- Decision tree
- Naïve Bayes
- Random forest
- Logistic regression
- K-nearest neighbor (KNN)
Regression
This method is used when the predicted data is numerical. If the shopkeeper wants to predict the price of a product based on its demand, he will choose regression.
Clustering
Clustering is a type of unsupervised learning and is used when the data needs to be organized. Flipkart, Amazon, and other online retailers use clustering for their recommendation systems. Search engines also use clustering to analyze your search history to determine your preferences and provide you the best search results. One of the algorithms that fall under clustering is K-means.
In the next section of the introduction to machine learning tutorial, we will learn about the top common machine learning algorithms.
4 Most Common Machine Learning Algorithms

The four most commonly used ML algorithms include:
- K-nearest neighbor
- Linear regression
- Decision tree
- Naïve Bayes
K-Nearest Neighbor
K-nearest neighbor is a type of classification algorithm where similar data points form clusters, and those clusters are used to identify new, unknown objects. In the image below, there are three different clusters: blue, red, and green.
If you get a new and unknown data point, it is classified based on the cluster closest to it or the most similar to it. K in KNN is the number of nearest neighboring data points we wish to compare the unknown data with. Consider the example below:

There are three clusters in a cost to durability graph: footballs, tennis balls, and basketballs. From the graph, we can infer that:
- The cost of footballs is high, and the durability is low
- The tennis balls have high durability, but low cost
- The cost of basketballs is as high as the durability
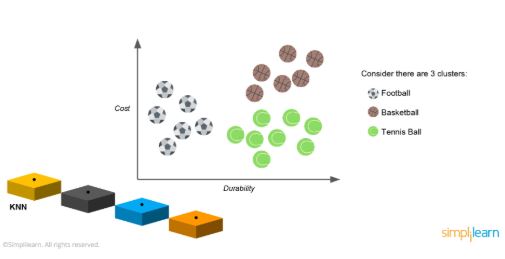
Consider an unknown data point: a black spot, which can be one classification of balls.
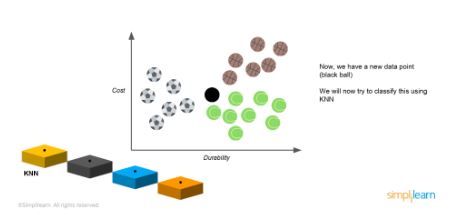
We try to classify this using KNN. If you take k=5, draw a circle keeping the unknown data point in the center, and make sure that you have five balls inside that circle.
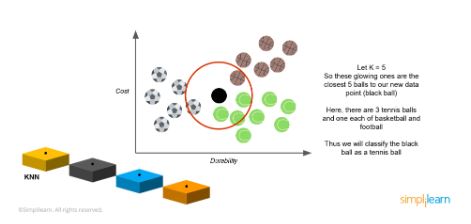
After you draw a circle, you have one football, one basketball, and three tennis balls inside it. Since you have the highest number of tennis balls inside the circle, the ball will be classified as a tennis ball. This is how k-nearest neighbor classification is done.
Linear Regression
Linear regression is a type of supervised learning algorithm used to establish a linear relationship between variables, one of which would be dependent and another independent. If you want to predict the weight of a person based on his height, the weight would be the dependent variable, and height would be independent.
See the following example:
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Consider a graph showing a relationship between the height and weight of a person. The y-axis represents the height, and the x-axis represents weight. The green dots are the various data points, and “d” is the mean squared error, which is the perpendicular distance from the line to the data points, or the error values. This error depicts how much the predicted values vary from the original value.

For now, ignore the blue line, and let’s draw a new regression line. You can see the distance from all the data points to the new line. If you take the new line as a regression line, the error in the prediction will be too high. In this case, the model will not be able to give you an accurate forecast.

Let’s demonstrate the same with another regression line, as shown below. Even in this case, the perpendicular distance of the data points from the line is very high, meaning the error value is still too high. This model will also not give you an accurate prediction.

Finally, you draw a line (the blue line) that maps the distance of the data points from the line, which is much less relative to the other two lines you drew. The value of “d” for the blue regression line will be much less and therefore, more accurate. If you assign any value to the x-axis, the corresponding value of the y-axis will be your prediction. Given the fact that “d” is very low, your prediction should be accurate.

This is how regression works; you draw a regression line in such a way that the value of “d” is the least, eventually giving you accurate predictions.
Decision Tree
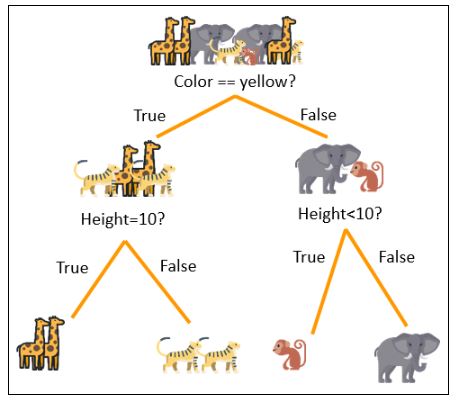
The decision tree is an algorithm people can relate to as it’s often how we make decisions ourselves. It uses a branching method to understand the problem and make decisions based on the conditions.
Imagine sitting at home and thinking about going for a swim. You check if it’s sunny outside: That’s your first condition. If the answer to that condition is “yes,” you go for a swim. If it’s not sunny, the next question you ask is, “Is it raining?” That’s the second condition. If it’s raining, you cancel your plans and stay indoors. Otherwise, you would go outside and take a walk. That’s the final node.
That’s how the decision tree algorithm works. You probably use this every day to make decisions based on the answers to multiple conditions.
Naïve Bayes
Naïve Bayes is mostly used in cases where a prediction needs to be made based on a large data set. It makes use of conditional probability — the probability of an event, say “A,” happening given that another event, “B,” has already happened.
Example 1: Filtering spam email
This algorithm is most commonly used in filtering spam emails in your email account.
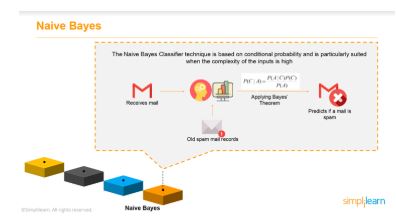
When you receive an email, the model goes through your old spam email records. Then, it uses Bayes theorem to predict if the incoming email is spam or not.

P (C/A) is the probability of event “C” occurring when “A” has already occurred.
P (A /C) is the probability of event “A” occurring when “C” has already occurred.
P(C) is the probability of event “C” occurring.
P(A) is the probability of the event “A” occurring.
Example 2: Predict a game of cricket
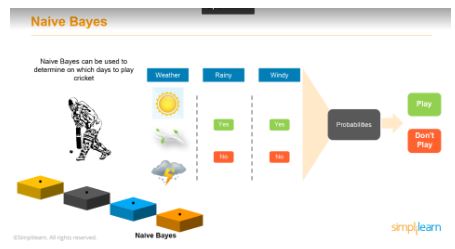
In another example, Naïve Bayes can be used to determine which days to play cricket. Based on the probabilities of a day being rainy, windy, or sunny, the model tells you if a cricket match is possible. If you consider all the weather conditions to be “event A” and the probability of a match being possible “event C,” the model applies the probabilities of event A and C into the Bayes theorem and predicts if a game of cricket is possible on a particular day or not. In this case, if the probability of C/A is more than 0.5, then you can play a game of cricket. If it’s less than 0.5, you won’t be able to.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Practical Use Case: Predict the Price of a House Using Machine Learning Basics
In this section of the introduction to machine learning tutorial, we will discuss some amazing use cases of machine learning. This use case regards predicting the price of a house using machine learning basics. In this example, a person is planning to sell his house but is unable to decide on a selling price.

Problem statement – “predict the price of a house using machine learning basics, implemented in Python.”
Which algorithm should you use for this use case?
For this problem, we use linear regression, which is a type of supervised learning. It is most suitable over other algorithms because:

- The output is quantitative and directly proportional to the variables. As mentioned before, if the prediction is quantitative, linear regression is the best choice
- The second reason is the low computation cost. This means that if you use an algorithm that involves a lot of equation solving, you’ll need a compelling system, and that will cost you more. However, this is not the case with a linear regression, which is a very simple algorithm that can be done in any normal system
- Finally, linear regression is easy to understand
Use Case Data Variables

Your data set has the following features; you need to take them all into consideration to predict the price of the house:
- The low status of the population in that area
- The mean price of all the houses in that area
- Age of home
- Tax rate
- Average number of rooms in every house
- Distance to five Boston employments
- Accessibility to highways
- Per capita crime rate
How Linear Regression Works

This is how linear regression works:
You will provide your model (the computer) with training data (all the features/data variables) so that it can learn from it. You will then provide your model with test data, i.e., specific values that it needs to predict. From the training data that is acquired, it will be able to predict the price of the house.
Implement the model in Python
To implement the entire model on Python, we use:
- Jupyter Notebook to run the code
- Scikit-learn to load all the data and libraries. Scikit-learn is a library dedicated explicitly to machine learning if you are programming in Python
- Start by importing the required libraries for the model from scikit-learn.
First comes NumPy, support for large arrays, and matrices that we would use in this use case.
![]()
Then comes Pandas, a package that makes working with relational data easier.
![]()
Next is the regression model that we are going to use.
![]()
To check the accuracy of the model, we import train tests split.
![]()
Now press Shift + Enter to run the cell.
2. Load the Boston data set from scikit-learn
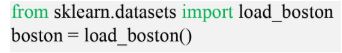
Press Shift + Enter to run the cell.
3. Have a look at the data set
Type “Boston” and hit enter. You should see the entire data set.

4. Divide the data into two different data frames

Here’s where the Pandas library comes into play. All the target values will be loaded in the df_y data frame. Run the cell.
5. Describe the data
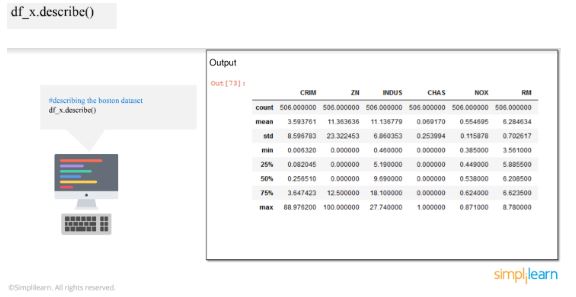
This table provides you with the count of every feature, the mean value for every feature, and the standard deviation.
6. Apply linear regression
![]()
Press shift + enter
7. Split the data into train and test data to validate the model
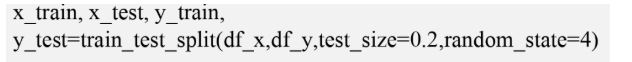
Note: Size is equal to 0.2, which means 20 percent is test data, and the rest is train. The random state is needed when running and validating our model multiple times.
8. Fit the data into the regression function
Press Shift+Enter

You can see that the data set is fit into the function that you called before (line 14 in our illustration).
9. Check the coefficients

Press Shift+Enter and you will get this output
The coefficients give us an idea of how much the dependent variable will increase if the independent variable value increases by one. For instance, if you take the equation of a line, let’s say with the regression line y= mx+c, C is the constant and M is the coefficient in this case.
10. Predict the prices
![]()
The variable “a” is the predicted price. This will predict the prices according to arrays. Press Shift+Enter.
Next, enter the array number. The number in brackets (Line 19 in the image below) specifies the array number. In this example, the array is three. After pressing enter, the array value returned is 18. 15. Next, check on the test data to confirm the value for array number three. In this case, it is 19.3. You can see that the predicted value and the original value don’t vary much; the predictions are fairly good.
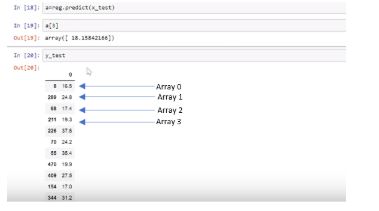
Let’s test another array, and in this example, we’ll use number five. In the test table, array number five is 24.2, and the predicted number is 25.4. The prediction is still perfect, and you can see the model is functioning well.

11. Find the error
![]()
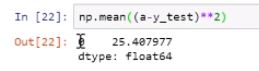
Variable “a” is the predicted value, and “y” is the test value. This gives you the error. If you square this value, you get the mean squared error.
Press Shift+Enter to reveal the value. From this illustration, the mean squared error value is 25.4.
At this point, you have successfully created a linear regression model. The error value you get in the predictions can be improved if the data is manipulated. The lesser the mean squared error, the more accurate the predictions you get.
Become an Artificial Intelligence Innovator
Kick-start Your AI & ML Career with UsStart Learning![]()
Summary
We hope this introduction to machine learning tutorial has been helpful and that you now have a better understanding of machine learning basics and how it affects our day-to-day lives. With a little more practice, you will become adept at applying the supervised, unsupervised and reinforcement machine learning methods to make predictions with different types of data. These methods are necessary to master if you are planning on becoming a machine learning engineer. As an aspirant, you can enroll in Simplilearn’s Caltech Post Graduate Program in AI And Machine Learning to receive training from industry experts or self-paced learning. The course will not only enhance your theoretical knowledge of machine learning, but it will also provide hands-on experience through real-life industry projects in integrated cloud labs. Contact Simplilearn to learn more about your learning options.





