A tutorial on building a semantic paper engine using RAG with LangChain, Chainlit copilot apps, and Literal AI observability.
![]() 17 min read
17 min read
12 hours ago
In this guide, I’ll demonstrate how to build a semantic research paper engine using Retrieval Augmented Generation (RAG). I’ll utilize LangChain as the main framework for building our semantic engine, along-with OpenAI’s language model and Chroma DB’s vector database. For building the Copilot embedded web application, I’ll use Chainlit’s Copilot feature and incorporate observability features from Literal AI. This tool can facilitate academic research by making it easier to find relevant papers. Users will also be able to interact directly with the content by asking questions about the recommended papers. Lastly, we will integrate observability features in the application to track and debug calls to the LLM.
App Schema for Copilot-embedded semantic research paper application. Illustration by Author.
Here is an overview of everything we will cover in this tutorial:
- Develop a RAG pipeline with OpenAI, LangChain and Chroma DB to process and retrieve the most relevant PDF documents from the arXiv API.
- Develop a Chainlit application with a Copilot for online paper retrieval.
- Enhance the application with LLM observability features with Literal AI.
Copilot-embedded semantic research paper application in action. By Author
Code for this tutorial can be found in this GitHub repo:
Create a new conda environment:
conda create -n semantic_research_engine python=3.10
Activate the environment:
conda activate semantic_research_engine
Install all required dependencies in your activated environment by running the following command:
pip install -r requirements.txt
Retrieval Augmented Generation (RAG) is a popular technique that allows you to build custom conversational AI applications with your own data. The principle of RAG is fairly simple: we convert our textual data into vector embeddings and insert these into a vector database. This database is then linked to a large language model (LLM). We are constraining our LLM to get information from our own database instead of relying on prior knowledge to answer user queries. In the next few steps, I will detail how to do this for our semantic research paper engine. We will create a test script named rag_test.py to understand and build the components for our RAG pipeline. These will be reused when building our Copilot integrated Chainlit application.
Step 1
Secure an OpenAI API key by registering an account. Once done, create a .env file in your project directory and add your OpenAI API key as follows:
OPENAI_API_KEY=”your_openai_api_key”
This .env will house all of our API keys for the project.
Step 2: Ingestion
In this step, we will create a database to store the research papers for a given user query. To do this, we first need to retrieve a list of relevant papers from the arXiv API for the query. We will be using the ArxivLoader() package from LangChain as it abstracts API interactions, and retrieves the papers for further processing. We can split these papers into smaller chunks to ensure efficient processing and relevant information retrieval later on. To do this, we will use the RecursiveTextSplitter() from LangChain, since it ensures semantic preservation of information while splitting documents. Next, we will create embeddings for these chunks using the sentence-transformers embeddings from HuggingFace. Finally, we will ingest these split document embeddings into a Chroma DB database for further querying.
# rag_test.py
from langchain_community.document_loaders import ArxivLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
query = “lightweight transformer for language tasks”
arxiv_docs = ArxivLoader(query=query, load_max_docs=3).load()
pdf_data = []
for doc in arxiv_docs:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100)
texts = text_splitter.create_documents([doc.page_content])
pdf_data.append(texts)
embeddings = HuggingFaceEmbeddings(model_name=”sentence-transformers/all-MiniLM-l6-v2″)
db = Chroma.from_documents(pdf_data[0], embeddings)
Step 3: Retrieval and Generation
Once the database for a particular topic has been created, we can use this database as a retriever to answer user questions based on the provided context. LangChain offers a few different chains for retrieval, the simplest being the RetrievalQA chain that we will use in this tutorial. We will set it up using the from_chain_type() method, specifying the model and the retriever. For document integration into the LLM, we’ll use the stuff chain type, as it stuffs all documents into a single prompt.
# rag_test.py
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
llm = OpenAI(model=’gpt-3.5-turbo-instruct’, temperature=0)
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type=”stuff”,
retriever=db.as_retriever())
question = “how many and which benchmark datasets and tasks were
compared for light weight transformer?”
result = qa({“query”: question})
Now that we have covered online retrieval from the arXiv API and the ingestion and retrieval steps for our RAG pipeline, we are ready to develop the web application for our semantic research engine.
Literal AI is an observability, evaluation and analytics platform for building production-grade LLM apps. Some key features offered by Literal AI include:
- Observability: enables monitoring of LLM apps, including conversations, intermediary steps, prompts, etc.
- Datasets: allows creation of datasets mixing production data and hand written examples.
- Online Evals: enables evaluation of threads and execution in production using different evaluators.
- Prompt Playground: allows iteration, versioning, and deployment of prompts.
We will use the observability and prompt iteration features to evaluate and debug the calls made with our semantic research paper app.
When creating conversational AI applications, developers need to iterate through multiple versions of a prompt to get to the one that generates the best results. Prompt engineering plays a crucial role in most LLM tasks, as minor modifications can significantly alter the responses from a language model. Literal AI’s prompt playground can be used to streamline this process. Once you select the model provider, you can input your initial prompt template, add any additional information, and iteratively refine the prompts to find the most suitable one. In the next few steps, we will be using this playground to find the best prompt for our application.
Step 1
Create an API key by navigating to the Literal AI Dashboard. Register an account, navigate to the projects page, and create a new project. Each project comes with its unique API key. On the Settings tab, you will find your API key in the API Key section. Add it to your .env file:
LITERAL_API_KEY=”your_literal_api_key”
Step 2
In the left sidebar, click Prompts, and then navigate to New Prompt. This should open a new prompt creation session.
Literal AI Prompts Dashboard. Image by Author
Once inside the playground, on the left sidebar, add a new System message in the Template section. Anything in parenthesis will be added to the Variables, and treated as input in the prompt:
You are a helpful assistant. Use provided {{context}} to answer user
{{question}}. Do not use prior knowledge.
Answer:
In the right sidebar, you can provide your OpenAI API Key. Select parameters such as the Model, Temperature, and Maximum Length for completion to play around with the prompt.
Literal AI’s Prompt Playground. Image by Author
Once you are satisfied with a prompt version, click Save. You will be prompted to enter a name for your prompt, and an optional description. We can add this version to our code. In a new script named search_engine.py, add the following code:
#search_engine.py
from literalai import LiteralClient
from dotenv import load_dotenv
load_dotenv()
client = LiteralClient()
# This will fetch the champion version, you can also pass a specific version
prompt = client.api.get_prompt(name=”test_prompt”)
prompt = prompt.to_langchain_chat_prompt_template()
prompt.input_variables = [“context”, “question”]
Literal AI allows you to save different runs of a prompt, with a version feature. You can also view how each version is different from the previous one. By default, the champion version is pulled. If you want to change a version to be the champion version, you can select it in the playground, and then click on Promote.
Literal AI Prompt Versions. Image by Author
Once the above code has been added, we will be able to view generations for specific prompts in the Literal AI Dashboard (more on this later).
Chainlit is an open-source Python package designed to build production-ready conversational AI applications. It provides decorators for several events (chat start, user message, session resume, session stop, etc.). You can check out my article below for a more thorough explanation:
Specifically in this tutorial, we will focus on building a Software Copilot for our RAG application using Chainlit. Chainlit Copilot offers contextual guidance and automated user actions within applications.
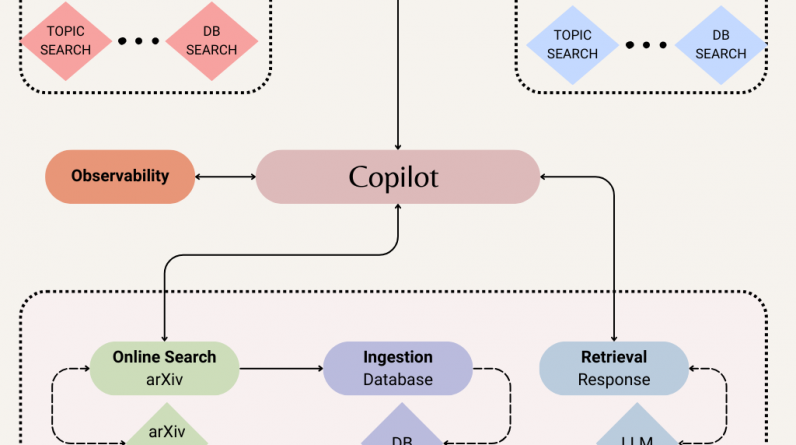
Research paper app schema with relevant tools. Illustration by Author.
Embedding a copilot in your application website can be useful for several reasons. We will build a simple web interface for our semantic research paper engine, and integrate a copilot inside it. This copilot will have a few different features, but here are the most prominent ones:
- It will be embedded inside our website’s HTML file.
- The copilot will be able to take actions on behalf of the user. Let’s say the user asks for online research papers on a specific topic. These can be displayed in a modal, and we can configure our copilot to do this automatically without needing user inputs.
In the next few steps, I will detail how to create a software copilot for our semantic research engine using Chainlit.
Step 1
The first step involves writing logic for our chainlit application. We will use two chainlit decorator functions for our use case: @cl.on_chat_start and @cl.on_message. We will add the logic from the online search and RAG pipeline to these functions. A few things to remember:
- @cl.on_chat_start contains all code required to be executed at the start of a new user session.
- @cl.on_message contains all code required to be executed when a user sends in a new message.
We will encapsulate the entire process from receiving a research topic to creating a database and ingesting documents within the @cl.on_chat_start decorator. In the search_engine.py script, import all necessary modules and libraries:
# search_engine.py
import chainlit as cl
from langchain_community.document_loaders import ArxivLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
Let’s now add the code for the @cl.on_chat_start decorator. We will make this function asynchronous to ensure multiple tasks can run concurrently.
# search_engine.py
# contd.
@cl.on_chat_start
async def retrieve_docs():
# QUERY PORTION
arxiv_query = None
# Wait for the user to send in a topic
while arxiv_query is None:
arxiv_query = await cl.AskUserMessage(
content=”Please enter a topic to begin!”, timeout=15).send()
query = arxiv_query[‘output’]
# ARXIV DOCS PORTION
arxiv_docs = ArxivLoader(query=arxiv_query, load_max_docs=3).load()
# Prepare arXiv results for display
arxiv_papers = [f”Published: {doc.metadata[‘Published’]} n “
f”Title: {doc.metadata[‘Title’]} n “
f”Authors: {doc.metadata[‘Authors’]} n “
f”Summary: {doc.metadata[‘Summary’][:50]}… n—n”
for doc in arxiv_docs]
await cl.Message(content=f”{arxiv_papers}”).send()
await cl.Message(content=f”Downloading and chunking articles for {query} “
f”This operation can take a while!”).send()
# DB PORTION
pdf_data = []
for doc in arxiv_docs:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=100)
texts = text_splitter.create_documents([doc.page_content])
pdf_data.append(texts)
llm = ChatOpenAI(model=’gpt-3.5-turbo’,
temperature=0)
embeddings = HuggingFaceEmbeddings(
model_name=”sentence-transformers/all-MiniLM-l6-v2″)
db = Chroma.from_documents(pdf_data[0], embeddings)
# CHAIN PORTION
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type=”stuff”,
retriever=db.as_retriever(),
chain_type_kwargs={
“verbose”: True,
“prompt”: prompt
}
)
# Let the user know that the pipeline is ready
await cl.Message(content=f”Database creation for `{query}` complete. “
f”You can now ask questions!”).send()
cl.user_session.set(“chain”, chain)
cl.user_session.set(“db”, db)
Let’s go through the code we have wrapped in this function:
- Prompting user query: We begin by having the user send in a research topic. This function will not proceed until the user submits a topic.
- Online Search: We retrieve relevant papers using LangChain’s wrapper for arXiv searches, and display the relevant fields from each entry in a readable format.
- Ingestion: Next, we chunk the articles and create embeddings for further processing. Chunking ensures large papers are handled efficiently. Afterward, a Chroma database is created from processed document chunks and embeddings.
- Retrieval: Finally, we set up a RetrievalQA chain, integrating the LLM and the newly created database as a retriever. We also provide the prompt we created earlier in our Literal AI playground.
- Storing variables: We store the chain and db in variables using the cl.user_session.set functionality for reuse later on.
- User messages: We use Chainlit’s cl.Message functionality throughout the function to interact with the user.
Let’s now define our @cl.on_message function, and add the generation portion of our RAG pipeline. A user should be able to ask questions from the ingested papers, and the application should provide relevant answers.
@cl.on_message
async def retrieve_docs(message: cl.Message):
question = message.content
chain = cl.user_session.get(“chain”)
db = cl.user_session.get(“db”)
# Create a new instance of the callback handler for each invocation
cb = client.langchain_callback()
variables = {“context”: db.as_retriever(search_kwargs={“k”: 1}),
“query”: question}
database_results = await chain.acall(variables,
callbacks=[cb])
results = [f”Question: {question} “
f”n Answer: {database_results[‘result’]}”]
await cl.Message(results).send()
Here is a breakdown of the code in the function above:
- Chain and Database Retrieval: We first retrieve the previously stored chain and database from the user session.
- LangChain Callback Integration: To ensure we can track our prompt and all generations that use a particular prompt version, we need to add the LangChain callback handler from Literal AI when invoking our chain. We are creating the callback handler using the langchain_callback() method from the LiteralClient instance. This callback will automatically log all LangChain interactions to Literal AI.
- Generation: We define the variables: the database as the context for retrieval and the user’s question as the query, also specifying to retrieve the top result (k: 1). Finally, we call the chain with the provided variables and callback.
Step 2
The second step involves embedding the copilot in our application website. We will create a simple website for demonstration. Create an index.html file and add the following code to it:
In the code above, we have embedded the copilot inside our website by pointing to the location of the Chainlit server hosting our app. The window.mountChainlitWidget adds a floating button on the bottom right corner of your website. Clicking on it will open the Copilot. To ensure our Copilot is working correctly, we need to first run our Chainlit application. Navigate inside your project directory and run:
chainlit run search_engine.py -w
The code above runs the application on https://localhost:8000. Next, we need to host our application website. Opening the index.html script inside a browser doesn’t work. Instead, we need to create an HTTPS testing server. You can do this in different ways, but one straightforward approach is to use npx. npx is included with npm (Node Package Manager), which comes with Node.js. To get npx, you simply need to install Node.js on your system. Navigate inside your directory and run:
npx http-server
Running the command above will serve our website at Navigate to the address and you will be able to see a simple web interface with the copilot embedded.
Launching the Copilot. Image by Author
Since we will be using the @cl.on_chat_start wrapper function to welcome users, we can set the show_readme_as_default to false in our Chainlit config to avoid flickering. You can find your config file in your project directory at .chainlit/config.toml.
Copilot Overview. Image by Author
Step 3
To execute the code only inside the Copilot, we can add the following:
@cl.on_message
async def retrieve_docs(message: cl.Message):
if cl.context.session.client_type == “copilot”:
# code to be executed only inside the Copilot
Any code inside this block will only be executed when you interact with your application from within your Copilot. For example, if you run a query at the Chainlit application interface hosted at https://localhost:8000, the code inside the above if block will not be executed, since it’s expecting the client type to be the Copilot. This is a helpful feature that you can use to differentiate between actions taken directly in the Chainlit application and those initiated through the Copilot interface. By doing so, you can tailor the behavior of your application based on the context of the request, allowing for a more dynamic and responsive user experience.
Step 4
The Copilot can call functions on your website. This is useful for taking actions on behalf of the user, such as opening a modal, creating a new document, etc. We will modify our Chainlit decorator functions to include two new Copilot functions. We need to specify in the index.html file how the frontend should respond when Copilot functions in our Chainlit backend application are activated. The specific reaction will vary based on the application. For our semantic research paper engine, we’ll generate pop-up notifications on the frontend whenever it’s necessary to show relevant papers or database answers in response to a user query.
Popups in response to user queries in the copilot. Image by Author
We will create two Copilot functions in our application:
- showArxivResults: this function will be responsible for displaying the online results pulled by the arxiv API against a user query.
- showDatabaseResults: this function will be responsible for displaying the results pulled from our ingested database against a user question.
First, let’s set up the backend logic in the search_engine.py script and modify the @cl.on_chat_start function:
@cl.on_chat_start
async def retrieve_docs():
if cl.context.session.client_type == “copilot”:
# same code as before
# Trigger popup for arXiv results
fn_arxiv = cl.CopilotFunction(name=”showArxivResults”,
args={“results”: “n”.join(arxiv_papers)})
await fn_arxiv.acall()
# same code as before
In the code above, a Copilot function named showArxivResults is defined and called asynchronously. This function is designed to display the formatted list of arXiv papers directly in the Copilot interface. The function signature is quite simple: we specify the name of the function and the arguments it will send back. We will use this information in our index.html file to create a popup.
Next, we need to modify our @cl.on_message function with the second Copilot function that will be executed when a user asks a question based on the ingested papers:
@cl.on_message
async def retrieve_docs(message: cl.Message):
if cl.context.session.client_type == “copilot”:
# same code as before
# Trigger popup for database results
fn_db = cl.CopilotFunction(name=”showDatabaseResults”,
args={“results”: “n”.join(results)})
await fn_db.acall()
# same code as before
In the code above, we have defined the second Copilot function named showDatabaseResults to be called asynchronously. This function is tasked with displaying the results retrieved from the database in the Copilot interface. The function signature specifies the name of the function and the arguments it will send back.
Step 5
We will now edit our index.html file to include the following changes:
- Add the two Copilot functions.
- Specify what would happen on our website when either of the two Copilot functions gets triggered. We will create a popup to display results from the application backend.
- Add simple styling for popups.
First, we need to add the event listeners for our Copilot functions. In the
Here is a breakdown of the above code:
- Includes functions to show (showPopup()) and hide (hidePopup()) the popup modal.
- An event listener is registered for the chainlit-call-fn event, which is triggered when a Copilot function (showArxivResults or showDatabaseResults) is called.
- Upon detecting an event, the listener checks the name of the Copilot function called. Depending on the function name, it updates the content of the relevant section within the popup with the results provided by the function. It replaces newline characters (\n) with HTML line breaks (
) to format the text properly for HTML display. - After updating the content, the popup modal is displayed (display: "flex"), allowing the user to see the results. The modal can be hidden using the close button, which calls the hidePopup() function.
Next, we need to define the popup modal we have specified above. We can do this by adding the following code to the
tag of our index.html script:
Arxiv Results
Online results will be displayed here.
Database Results
Database results will be displayed here.
Let’s also add some styling for our popups. Edit the
tag of the index.html file:
Now that we have added our Copilot logic to our Chainlit application, we can run both our application and the website. For the Copilot to work, our application must already be running. Open a terminal inside your project directory, and run the following command to launch the Chainlit server:
chainlit run search.py -h
In a new terminal, launch the website using:
npx http-serverApp Demo. By Author
Integrating observability features into a production-grade application, such as our Copilot-run semantic research engine, is typically required to ensure the application’s reliability in a production environment. We will be using this with the Literal AI framework.
For any Chainlit application, Literal AI automatically starts monitoring the application and sends data to the Literal AI platform. We already initiated the Literal AI client when creating our prompt in the search_engine.py script. Now, each time the user interacts with our application, we will see the logs in the Literal AI dashboard.
Navigate to the Literal AI Dashboard, select the project from the left panel, and then click on Observability. You will see logs for the following features.
Threads
A thread represents a conversation session between an assistant and a user. You should be able to see all the conversations a user has had in the application.
Literal AI Threads. Image by Author
Expanding on a particular conversation will give key details, such as the time each step took, details of the user message, and a tree-based view detailing all steps. You can also add a conversation to a dataset.
Literal AI Thread Overview. Image by Author
Runs
A run is a sequence of steps taken by an agent or a chain. This gives details of all steps taken each time a chain or agent is executed. With this tab, we get both the input and the output for each user query.
Literal AI Runs Dashboard. Image by Author
You can expand on a run, and this will give further details. Once again, you can add this info to a dataset.
Literal AI Run Overview. Image by Author
Generations
A generation contains both the input sent to an LLM and its completion. This gives key details including the model used for a completion, the token count, as well as the user requesting the completion, if you have configured multiple user sessions.
Literal AI Generations Overview. Image by Author
We can track generations and threads against each prompt created and used in the application code since we added LangChain integrations. Therefore, each time the chain is invoked for a user query, logs are added against it in the Literal AI dashboard. This is helpful to see which prompts were responsible for a particular generation, and compare performance for different versions.
Copilot integrated semantic research engine app with observability features. Image by Author
In this tutorial, I demonstrated how to create a semantic research paper engine using RAG features with LangChain, OpenAI, and ChromaDB. Additionally, I showed how to develop a web app for this engine, integrating Copilot and observability features from Literal AI. Incorporating evaluation and observability is generally required for ensuring optimal performance in real-world language model applications. Furthermore, the Copilot can be an extremely useful feature for different software applications, and this tutorial can be a good starting point to understand how to set it up for your application.
You can find the code from this tutorial on my GitHub. If you found this tutorial helpful, consider supporting by giving it fifty claps. You can follow along as I share working demos, explanations and cool side projects on things in the AI space. Come say hi on LinkedIn and X! I share guides, code snippets and other useful content there. 👋