Image by author
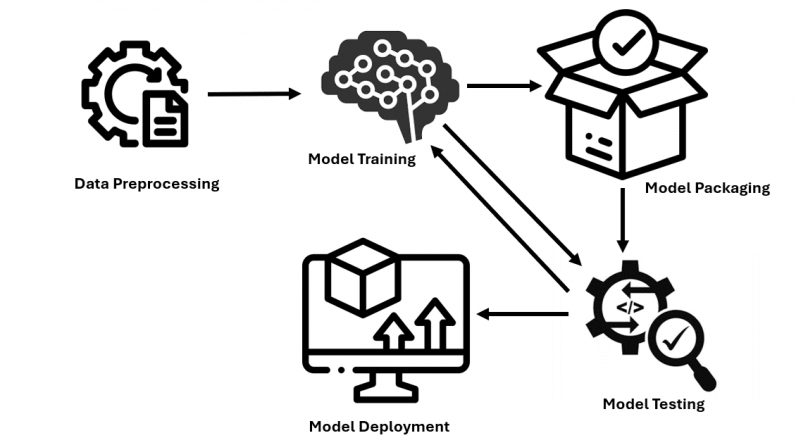
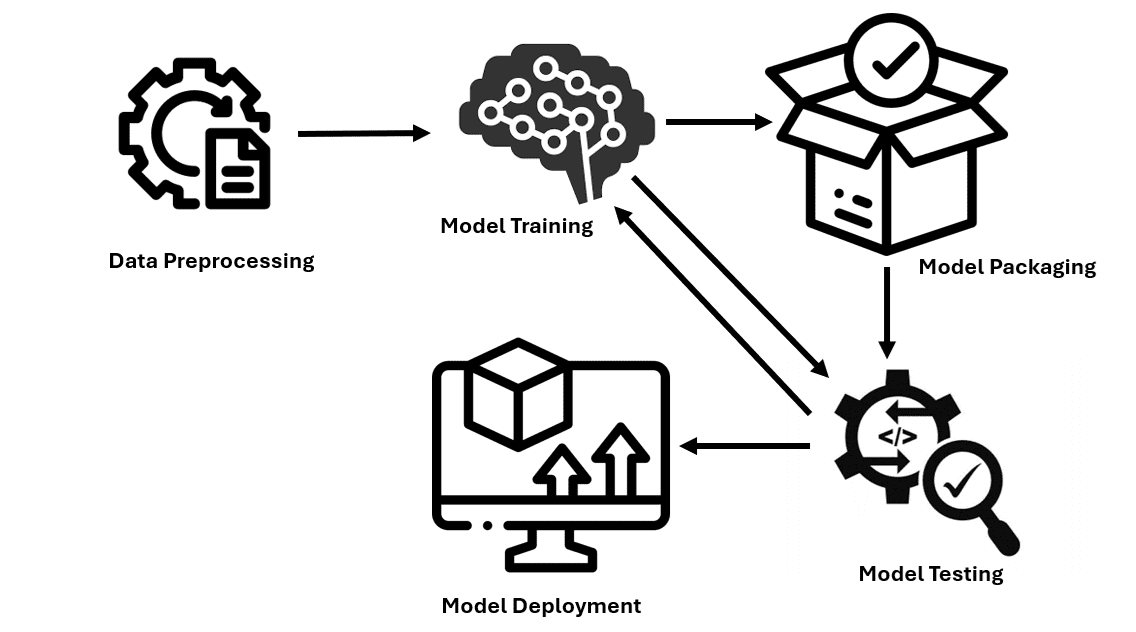
Model deployment is the process of trained models being integrated into practical applications. This includes defining the necessary environment, specifying how input data is introduced into the model and the output produced, and the capacity to analyze new data and provide relevant predictions or categorizations. Let us explore the process of deploying models in production.
Step 1: Data Preprocessing
Deal with missing values by imputing them using mean values or deleting the rows/columns. Ensure that categorical variables are also transformed from qualitative data to quantitative data by One-Hot Encoding or by Label Encoding. Normalize and standardize numerical features to transform them to a common scale.
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your data
df = pd.read_csv(‘your_data.csv’)
# Handle missing values
imputer_mean = SimpleImputer(strategy=’mean’)
df[‘numeric_column’] = imputer_mean.fit_transform(df[[‘numeric_column’]])
# Encode categorical variables
one_hot_encoder = OneHotEncoder()
encoded_features = one_hot_encoder.fit_transform(df[[‘categorical_column’]]).toarray()
encoded_df = pd.DataFrame(encoded_features, columns=one_hot_encoder.get_feature_names_out([‘categorical_column’]))
# Normalize and standardize numerical features
# Standardization (zero mean, unit variance)
scaler = StandardScaler()
df[‘standardized_column’] = scaler.fit_transform(df[[‘numeric_column’]])
# Normalization (scaling to a range of [0, 1])
normalizer = MinMaxScaler()
df[‘normalized_column’] = normalizer.fit_transform(df[[‘numeric_column’]])
Step 2: Model Training and Evaluation
Divide data into two groups: training data set and testing data set to train the model. Choose a model and train it to the used data. Fine-tuning hyperparameters selects the best-performing machine learning models. The model is checked for its stability with different sub-groups of the data for implementing cross-validation.
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
# Load your data
df = pd.read_csv(‘data.csv’)
# Split data into training and testing sets
X = df.drop(columns=[‘target_column’])
y = df[‘target_column’]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Hyperparameter tuning
param_grid = {
‘n_estimators’: [50, 100, 200],
‘max_depth’: [None, 10, 20, 30],
‘min_samples_split’: [2, 5, 10]
}
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring=’accuracy’,
n_jobs=-1)
# Fit the grid search to the data
grid_search.fit(X_train, y_train)
# Get the best model from the grid search
best_model = grid_search.best_estimator_
# Cross-validation to assess model generalization and robustness
cv_scores = cross_val_score(best_model, X_train, y_train, cv=5, scoring=’accuracy’)
print(f”Cross-validation scores: {cv_scores}”)
print(f”Mean cross-validation score: {cv_scores.mean()}”)
Step 3: Model Packaging
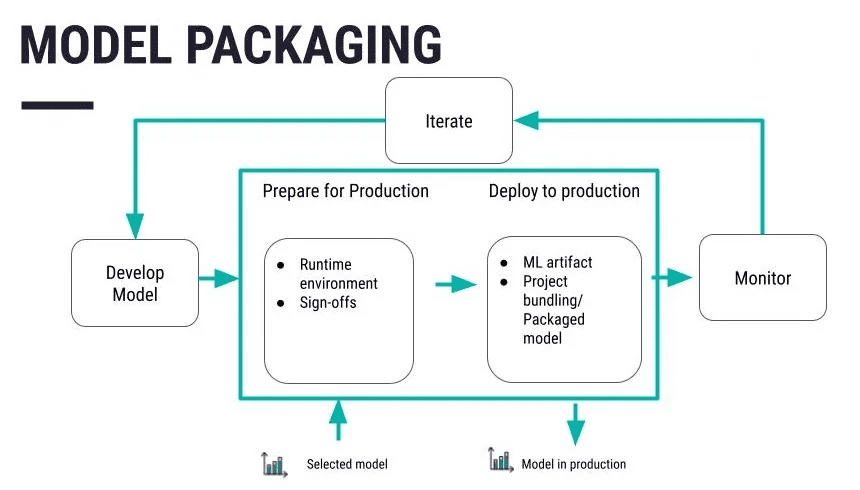
Source:
Serialize the code into a more suitable format that can be stored or distributed to the other system. Pickle is one of the conventional formats followed by joblib and ONNX formats based on the user’s requirements. After you have defined and optimized your model, store it in a file or database. Platforms such as Git also come in handy to handle the alterations and modifications to be made. Apply specific measures like encryption of data both while stored and in transit so that the data is not easily accessible to anyone else.
import joblib
joblib.dump(model, ‘model.pkl’)
Put your serialized model into a container such as Docker. This makes it portable and easier to transport machine learning models to different environments.
# Docker code
FROM python:3.8-slim
COPY model.pkl /app/model.pkl
COPY app.py /app/app.py
WORKDIR /app
RUN pip install -r requirements.txt
CMD [“python”, “app.py”]
Step 4: Environment Setup for Deployment
To set infrastructure and resources for model deployment, it is recommended to use cloud services like AWS, Azure, or Google Cloud. Modify the necessary components needed for hosting of the model such as servers, databases and all that can be done on the right cloud infrastructure services of the selected cloud platform.
AWS: Setup EC2 instance using AWS CLI
aws ec2 run-instances
–image-id ami-0abcdef1234567890
–count 1
–instance-type t2.micro
–key-name MyKeyPair
–security-group-ids sg-0abcdef1234567890
–subnet-id subnet-0abcdef1234567890
Azure: Setup Virtual Machine using Azure CLI
az vm create
–resource-group myResourceGroup
–name myVM
–image UbuntuLTS
–admin-username azureuser
–generate-ssh-keys
Google Cloud: Setup Compute Engine instance using Google Cloud CLI
gcloud compute instances create my-instance
–zone=us-central1-a
–machine-type=e2-medium
–subnet=default
–network-tier=PREMIUM
–maintenance-policy=MIGRATE
–image=debian-9-stretch-v20200902
–image-project=debian-cloud
–boot-disk-size=10GB
–boot-disk-type=pd-standard
–boot-disk-device-name=my-instance
Step 5: Building the Deployment Pipeline
Use such as Jenkins, or GitLab CI/CD to automate the step of deploying the model. Design a list of steps to be executed in order to make the deploymnt process more efficient and use a Jenkinsfile or YAML configuration in the context of GitHub Actions.
# Using Jenkins for CI/CD pipeline
pipeline {
agent any
stages {
stage(‘Build’) {
steps {
sh ‘python setup.py build’
}
}
stage(‘Test’) {
steps {
sh ‘python -m unittest discover’
}
}
stage(‘Deploy’) {
steps {
sh ‘docker build -t mymodel:latest .’
sh ‘docker run -d -p 5000:5000 mymodel:latest’
}
}
}
}
Step 6: Model Testing
Carry out tests to see to it that all the functions of the model are appropriately fulfilled. After that, the forecasted amounts are compared with the outcomes this model is supposed to provide. Check the model’s generalization capability to ascertain whether it will perform well on other new data. To compare with the sample data, choose the right evaluation criteria – accuracy, precision, recall.
# Import necessary libraries
from sklearn.metrics import accuracy_score, precision_score, recall_score
# Load your test data
test_df = pd.read_csv(‘your_test_data.csv’)
X_test = test_df.drop(columns=[‘target_column’])
y_test = test_df[‘target_column’]
# Predict outcomes on the test set
y_pred_test = best_model.predict(X_test)
# Evaluate performance metrics
test_accuracy = accuracy_score(y_test, y_pred_test)
test_precision = precision_score(y_test, y_pred_test, average=”weighted”)
test_recall = recall_score(y_test, y_pred_test, average=”weighted”)
# Print performance metrics
print(f”Test Set Accuracy: {test_accuracy}”)
print(f”Test Set Precision: {test_precision}”)
print(f”Test Set Recall: {test_recall}”)
Step 7: Monitoring and Maintenance
Make sure that there are no errors in the model with the help of tools such as AWS CloudWatch, Azure Monitor or Google Cloud Monitoring. This will require showing how the model deployed in the future should be modified to make it even better.
AWS CloudWatch
aws cloudwatch put-metric-alarm –alarm-name CPUAlarm –metric-name CPUUtilization
–namespace AWS/EC2 –statistic Average –period 300 –threshold 70
–comparison-operator GreaterThanThreshold –dimensions “Name=InstanceId,Value=i-1234567890abcdef0”
–evaluation-periods 2 –alarm-actions arn:aws:sns:us-east-1:123456789012:my-sns-topic
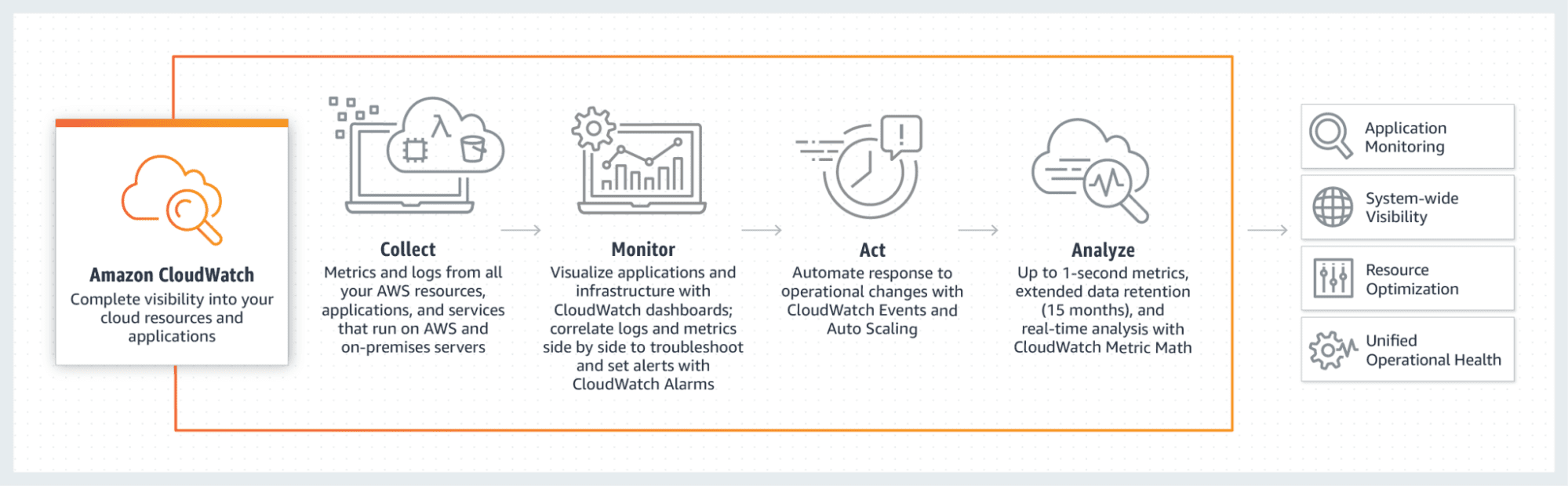
Source:
Azure Monitor
az monitor metrics alert create –name ‘CPU Alert’ –resource-group myResourceGroup
–scopes /subscriptions/{subscription-id}/resourceGroups/{resource-group-name}/providers/Microsoft.Compute/virtualMachines/{vm-name}
–condition “avg Percentage CPU > 80” –description ‘Alert if CPU usage exceeds 80%’
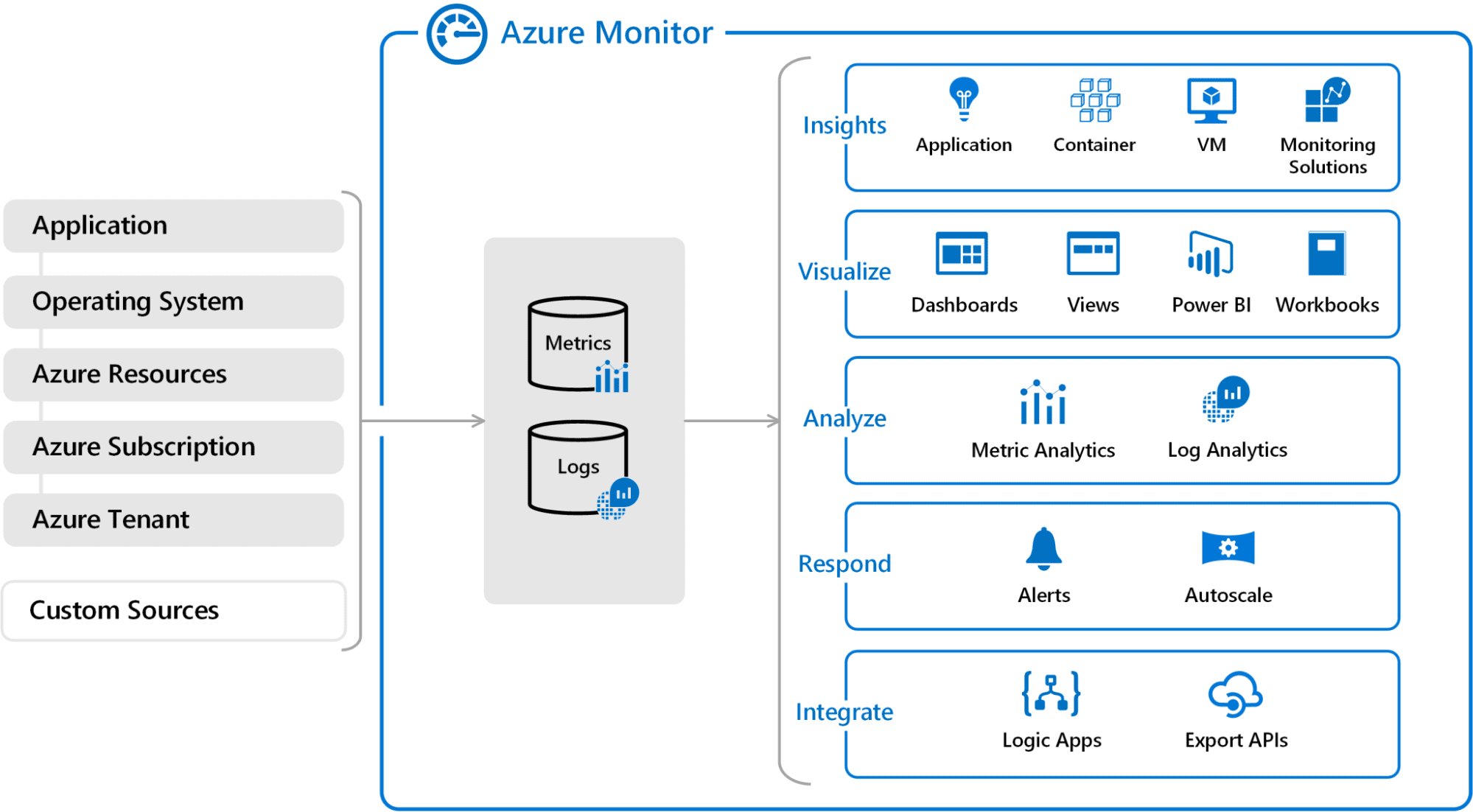
Source:
Wrapping Up
The strategies outlined in this tutorial will ensure that you have the key steps that are needed to make machine learning models deploy. Following the aforementioned steps, one can make the trained models usable and easily deployable for practice-based use. From building the model to configuring and validating the structure, you now know how to take your machine learning endeavors from hypothetical to practical.
Jayita Gulati is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. She holds a Master’s degree in Computer Science from the University of Liverpool.