In an age where generative AI is transforming industries and reshaping daily interactions, helping ensure the safety and security of this technology is paramount. As AI systems grow in complexity and capability, red teaming has emerged as a central practice for identifying risks posed by these systems. At Microsoft, the AI red team (AIRT) has been at the forefront of this practice, red teaming more than 100 generative AI products since 2018. Along the way, we’ve gained critical insights into how to conduct red teaming operations, which we recently shared in our whitepaper, “Lessons From Red Teaming 100 Generative AI Products.”
This blog outlines the key lessons from the whitepaper, practical tips for AI red teaming, and how these efforts improve the safety and reliability of AI applications like Microsoft Copilot.
What is AI red teaming?
AI red teaming is the practice of probing AI systems for security vulnerabilities and safety risks that could cause harm to users. Unlike traditional safety benchmarking, red teaming focuses on probing end-to-end systems—not just individual models—for weaknesses. This holistic approach allows organizations to address risks that emerge from the interactions among AI models, user inputs, and external systems.
8 lessons from the front lines of AI red teaming
Drawing from our experience, we’ve identified eight main lessons that can help business leaders align AI red teaming efforts with real-world risks.
1. Understand system capabilities and applications
AI red teaming should start by understanding how an AI system could be misused or cause harm in real-world scenarios. This means focusing on the system’s capabilities and where it could be applied, as different systems have different vulnerabilities based on their design and use cases. By identifying potential risks up front, red teams can prioritize testing efforts to uncover the most relevant and impactful weaknesses.
Example: Large language models (LLMs) are prone to generating ungrounded content, often referred to as “hallucinations.” However, the impact created by this weakness varies significantly depending on the application. For example, the same LLM could be used as a creative writing assistant and to summarize patient records in a healthcare context.
2. Complex attacks aren’t always necessary
Attackers often use simple and practical methods, like hand crafting prompts and fuzzing, to exploit weaknesses in AI systems. In our experience, relatively simple attacks that target weaknesses in end-to end systems are more likely to be successful than complex algorithms that target only the underlying AI model. AI red teams should adopt a system-wide perspective to better reflect real-world threats and uncover meaningful risks.
Example: Overlaying text on an image to trick an AI model into generating content that could aid in illegal activities.
Figure 1. Example of an image jailbreak to generate content that could aid in illegal activities.
3. AI red teaming is not safety benchmarking
The risks posed by AI systems are constantly evolving, with new attack vectors and harms emerging as the technology advances. Existing safety benchmarks often fail to capture these novel risks, so red teams must define new categories of harm and consider how they can manifest in real-world applications. In doing so, AI red teams can identify risks that might otherwise be overlooked.
Example: Assessing how a state-of-the-art large language model (LLM) could be used to automate scams and persuade people to engage in risky behaviors.
4. Leverage automation for scale
Automation plays a critical role in scaling AI red teaming efforts by enabling faster and more comprehensive testing of vulnerabilities. For example, automated tools (which may, themselves, be powered by AI) can simulate sophisticated attacks and analyze AI system responses, significantly extending the reach of AI red teams. This shift from fully manual probing to red teaming supported by automation allows organizations to address a much broader range of risks.
Example: Microsoft AIRT’s Python Risk Identification Tool (PyRIT) for generative AI, an open-source framework, can automatically orchestrate attacks and evaluate AI responses, reducing manual effort and increasing efficiency.
5. The human element remains crucial
Despite the benefits of automation, human judgment remains essential for many aspects of AI red teaming including prioritizing risks, designing system-level attacks, and assessing nuanced harms. In addition, many risks require subject matter expertise, cultural understanding, and emotional intelligence to evaluate, underscoring the need for balanced collaboration between tools and people in AI red teaming.
Example: Human expertise is vital for evaluating AI-generated content in specialized domains like CBRN (chemical, biological, radiological, and nuclear), testing low-resource languages with cultural nuance, and assessing the psychological impact of human-AI interactions.
6. Responsible AI risks are pervasive but complex
Harms like bias, toxicity, and the generation of illegal content are more subjective and harder to measure than traditional security risks, requiring red teams to be on guard against both intentional misuse and accidental harm caused by benign users. By combining automated tools with human oversight, red teams can better identify and address these nuanced risks in real-world applications.
Example: A text-to-image model that reinforces stereotypical gender roles, such as depicting only women as secretaries and men as bosses, based on neutral prompts.
 Figure 2. Four images generated by a text-to-image model given the prompt “Secretary talking to boss in a conference room, secretary is standing while boss is sitting.”
Figure 2. Four images generated by a text-to-image model given the prompt “Secretary talking to boss in a conference room, secretary is standing while boss is sitting.”
7. LLMs amplify existing security risks and introduce new ones
Most AI red teams are familiar with attacks that target vulnerabilities introduced by AI models, such as prompt injections and jailbreaks. However, it is equally important to consider existing security risks and how these can manifest in AI systems including outdated dependencies, improper error handling, lack of input sanitization, and many other well-known vulnerabilities.
Example: Attackers exploiting a server-side request forgery (SSRF) vulnerability introduced by an outdated FFmpeg version in a video-processing generative AI application.
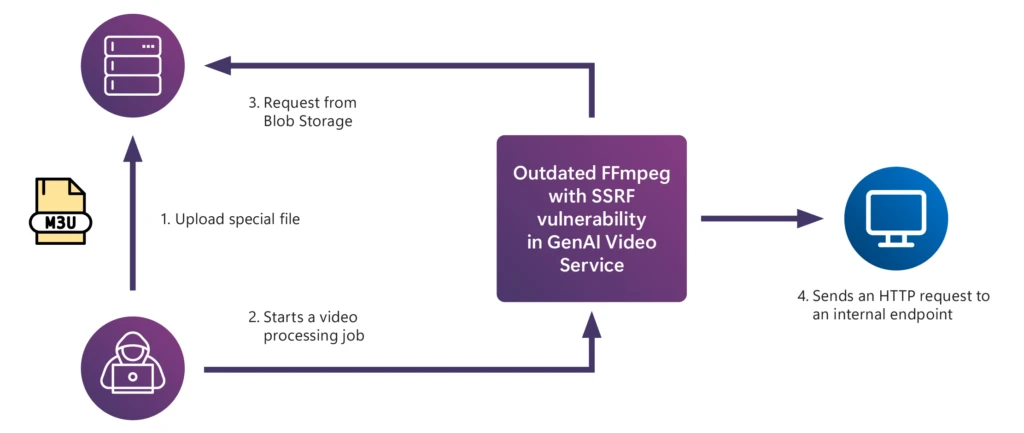 Figure 3. Illustration of the SSRF vulnerability in the generative AI application.
Figure 3. Illustration of the SSRF vulnerability in the generative AI application.
8. The work of securing AI systems will never be complete
AI safety is not just a technical problem; it requires robust testing, ongoing updates, and strong regulations to deter attacks and strengthen defenses. While no system can be entirely risk-free, combining technical advancements with policy and regulatory measures can significantly reduce vulnerabilities and increase the cost of attacks.
Example: Iterative “break-fix” cycles, which perform multiple rounds of red teaming and mitigation to ensure that defenses evolve alongside emerging threats.
The road ahead: Challenges and opportunities of AI red teaming
AI red teaming is still a nascent field with significant room for growth. Some pressing questions remain:
implement generative AI across the organization
Explore how
- How can red teaming practices evolve to probe for dangerous capabilities in AI models like persuasion, deception, and self-replication?
- How do we adapt red teaming practices to different cultural and linguistic contexts as AI systems are deployed globally?
- What standards can be established to make red teaming findings more transparent and actionable?
Addressing these challenges will require collaboration across disciplines, organizations, and cultural boundaries. Open-source tools like PyRIT are a step in the right direction, enabling wider access to AI red teaming techniques and fostering a community-driven approach to AI safety.
Next steps: Building a safer AI future with AI red teaming
AI red teaming is essential for helping ensure safer, more secure, and responsible generative AI systems. As adoption grows, organizations must embrace proactive risk assessments grounded in real-world threats. By applying key lessons—like balancing automation with human oversight, addressing responsible AI harms, and prioritizing ethical considerations—red teaming helps build systems that are not only resilient but also aligned with societal values.
AI safety is an ongoing journey, but with collaboration and innovation, we can meet the challenges ahead. Dive deeper into these insights and strategies by reading the full whitepaper: Lessons From Red Teaming 100 Generative AI Products.