


The input variables that we give to our machine learning models are called features. Each column in our dataset constitutes a feature. To train an optimal model, we need to make sure that we use only the essential features. If we have too many features, the model can capture the unimportant patterns and learn from noise. The method of choosing the important parameters of our data is called Feature Selection.
In this article titled ‘Everything you need to know about Feature Selection’, we will teach you all you need to know about feature selection.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
Why Feature Selection?
Machine learning models follow a simple rule: whatever goes in, comes out. If we put garbage into our model, we can expect the output to be garbage too. In this case, garbage refers to noise in our data.
To train a model, we collect enormous quantities of data to help the machine learn better. Usually, a good portion of the data collected is noise, while some of the columns of our dataset might not contribute significantly to the performance of our model. Further, having a lot of data can slow down the training process and cause the model to be slower. The model may also learn from this irrelevant data and be inaccurate.
Feature selection is what separates good data scientists from the rest. Given the same model and computational facilities, why do some people win in competitions with faster and more accurate models? The answer is Feature Selection. Apart from choosing the right model for our data, we need to choose the right data to put in our model.
Consider a table which contains information on old cars. The model decides which cars must be crushed for spare parts.

Figure 1: Old cars dataset
In the above table, we can see that the model of the car, the year of manufacture, and the miles it has traveled are pretty important to find out if the car is old enough to be crushed or not. However, the name of the previous owner of the car does not decide if the car should be crushed or not. Further, it can confuse the algorithm into finding patterns between names and the other features. Hence we can drop the column.

Figure 2: Dropping columns for feature selection
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
What is Feature Selection?
Feature Selection is the method of reducing the input variable to your model by using only relevant data and getting rid of noise in data.
It is the process of automatically choosing relevant features for your machine learning model based on the type of problem you are trying to solve. We do this by including or excluding important features without changing them. It helps in cutting down the noise in our data and reducing the size of our input data.
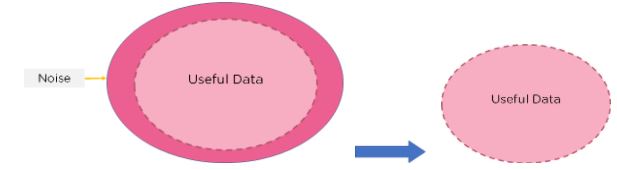
Figure 3: Feature Selection
Feature Selection Models
Feature selection models are of two types:
- Supervised Models: Supervised feature selection refers to the method which uses the output label class for feature selection. They use the target variables to identify the variables which can increase the efficiency of the model
- Unsupervised Models: Unsupervised feature selection refers to the method which does not need the output label class for feature selection. We use them for unlabelled data.
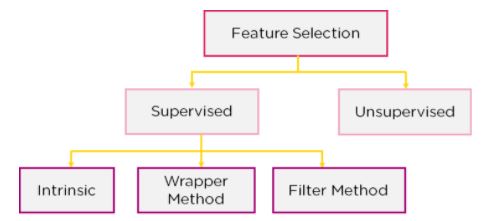
Figure 4: Feature Selection Models
We can further divide the supervised models into three :
1. Filter Method: In this method, features are dropped based on their relation to the output, or how they are correlating to the output. We use correlation to check if the features are positively or negatively correlated to the output labels and drop features accordingly. Eg: Information Gain, Chi-Square Test, Fisher’s Score, etc.
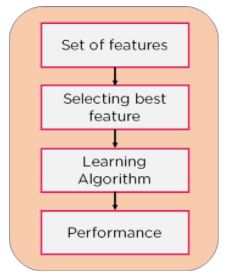
Figure 5: Filter Method flowchart
2. Wrapper Method: We split our data into subsets and train a model using this. Based on the output of the model, we add and subtract features and train the model again. It forms the subsets using a greedy approach and evaluates the accuracy of all the possible combinations of features. Eg: Forward Selection, Backwards Elimination, etc.
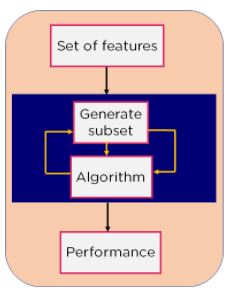
Figure 6: Wrapper Method Flowchart
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
3. Intrinsic Method: This method combines the qualities of both the Filter and Wrapper method to create the best subset.
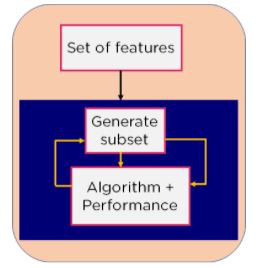
Figure 7: Intrinsic Model Flowchart
This method takes care of the machine training iterative process while maintaining the computation cost to be minimum. Eg: Lasso and Ridge Regression.
How to Choose a Feature Selection Model?
How do we know which feature selection model will work out for our model? The process is relatively simple, with the model depending on the types of input and output variables.
Variables are of two main types:
- Numerical Variables: Which include integers, float, and numbers.
- Categorical Variables: Which include labels, strings, boolean variables, etc.
Based on whether we have numerical or categorical variables as inputs and outputs, we can choose our feature selection model as follows:
|
Input Variable |
Output Variable |
Feature Selection Model |
|
Numerical |
Numerical |
|
|
Numerical |
Categorical |
|
|
Categorical |
Numerical |
|
|
Categorical |
Categorical |
|
Table 1: Feature Selection Model lookup
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Feature Selection With Python
Let’s get hands-on experience in feature selection by working on the Kobe Bryant Dataset which analyses shots taken by Kobe from different areas of the court to determine which ones will go into the basket.
The dataset is as shown:
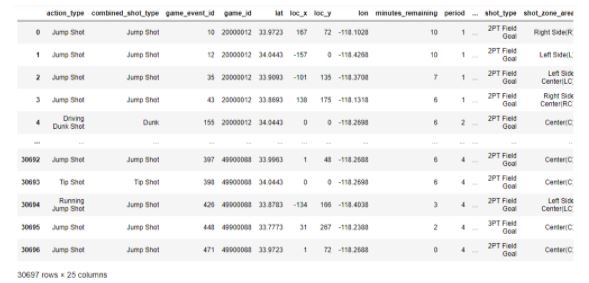
Figure 8: Kobe Bryant Dataset
As we can see, the dataset has 25 different columns. We will not need all of them.
We first begin by loading in the necessary modules.
Figure 9: Importing modules
First, let’s check out the loc_x and loc_y columns. They probably represent longitude and latitude.

Figure 10: Plotting the latitude and longitude columns in our dataset
The figure is as shown:
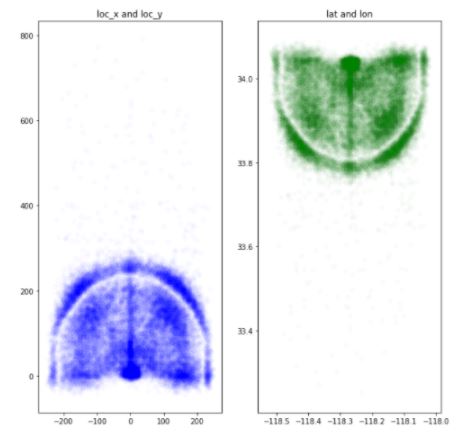
Figure 11: Plotting Latitude and Longitude
From the above figures, we can see that they resemble the two ‘D’s on a basketball court. Instead of having two separate columns, we can change the coordinates into polar form and have a single column [‘angle’].
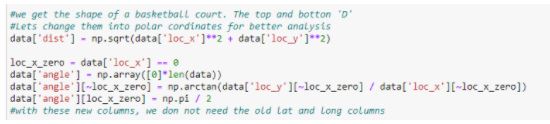
Figure 12: Changing Latitude and Longitude into polar form
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
We can combine the minutes and seconds columns into a single column for time.

Figure 13: Combining two columns
Let’s look at the unique values in the ‘team_id’ and ‘team_name’ columns:
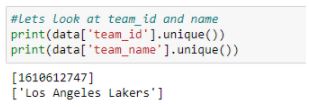
Figure 14: Unique values in ‘team_id’ and ‘team_name’
The entire column contains only one value and can be dropped. Let’s take a look at the ‘match_up’ and ‘opponent’ columns :

Figure 15: ‘match_up’ and ‘opponent’ columns
Again, they contain the same information. Let’s plot the values of ‘dist’ and ‘shot_distance’ columns on the same graph to see how they differ:
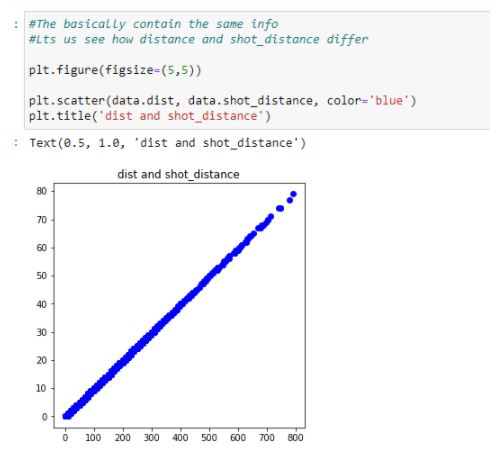
Figure 16: Plotting ‘dist’ and ‘shot_distance’ columns
Again, they contain exactly the same information. Let’s take a look at columns shot_zone_area, shot_zone_basic and shot_zone_range.
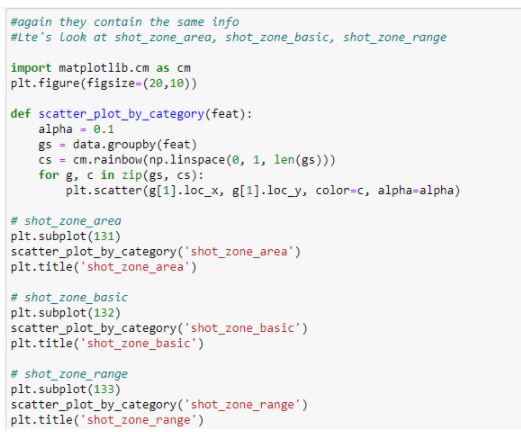
Figure 17: Plotting the different shot zones columns
The figure depicted below shows the plots :
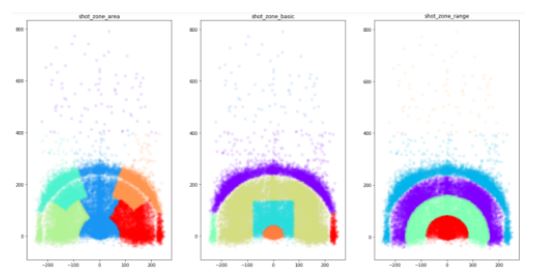
Figure 18: Different shot zones
We can see that they contain the different parts of the court from where the shots were taken. This information already exists in the angle and dist columns.
Now, let’s drop all the useless columns.

Figure 19: Dropping Columns
After merging columns and removing useless columns, we get a dataset that contains only 11 important columns.
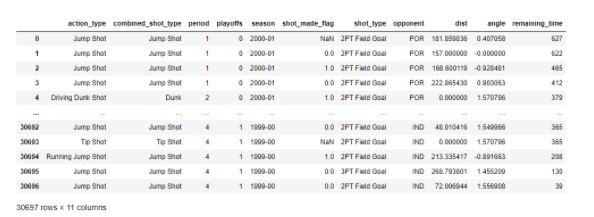
Figure 20: Final Dataset
Learn the essentials of object-oriented programming, web development with Django, and more with the Caltech Post Graduate Program In AI And Machine Learning. Enroll now!
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Conclusion
In this article titled ‘Everything you need to know about Feature Selection’, we got an idea of how important it is to select the best features for our machine learning model. We then took a look at what feature selection is and some feature selection models. We then moved onto a simple way to choose the right feature selection model based on the input and output values. Finally, we saw how to implement feature selection in Python with a demo. If you are looking to learn more about feature selection and related fundamental features of Python, Simplielarn’s Python Certification Course would be ideal for you. This python certification course covers the basics fundamentals of python including data operations, conditional statements, shell scripting, and Django and much more, and prepares you for a rewarding career as a professional Python programmer.
Was this article on feature selection useful to you? Do you have any doubts or questions for us? Mention them in this article’s comments section, and we’ll have our experts answer them for you at the earliest!






