


Python is one of the most widely used programming languages in the exciting field of data science. It leverages powerful machine learning algorithms to make data useful. One of those is K Nearest Neighbors, or KNN—a popular supervised machine learning algorithm used for solving classification and regression problems. The main objective of the KNN algorithm is to predict the classification of a new sample point based on data points that are separated into several individual classes. It is used in text mining, agriculture, finance, and healthcare.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
Why Do We Need the KNN Algorithm?
The KNN algorithm is useful when you are performing a pattern recognition task for classifying objects based on different features.
Suppose there is a dataset that contains information regarding cats and dogs. There is a new data point and you need to check if that sample data point is a cat or dog. To do this, you need to list the different features of cats and dogs.
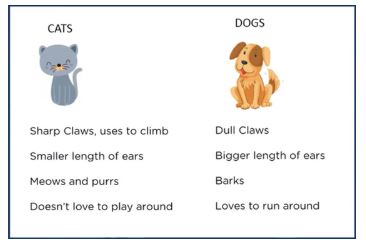
Now, let us consider two features: claw sharpness and ear length. Plot these features on a 2D plane and check where the data points fit in.
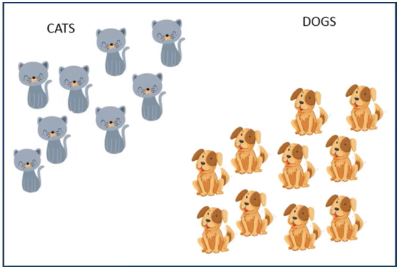
As illustrated above, the sharpness of claws is significant for cats, but not so much for dogs. On the other hand, the length of ears is significant for dogs, but not quite when it comes to cats.
Now, if we have a new data point based on the above features, we can easily determine if it’s a cat or a dog.
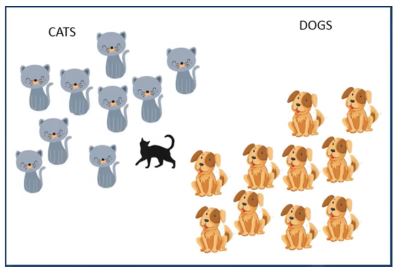
The new data point features indicate that the animal is, in fact, a cat.
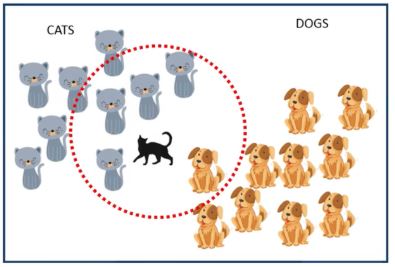
Since KNN is based on feature similarity, we can perform classification tasks using the KNN classifier. The image below—trained with the KNN algorithm—shows the predicted outcome, a black cat.
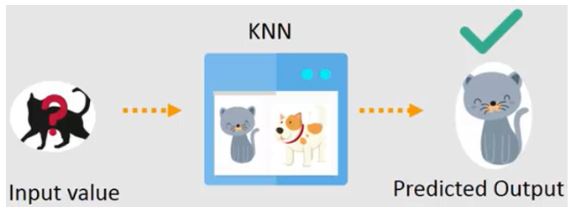
What is KNN?
K-Nearest Neighbors is one of the simplest supervised machine learning algorithms used for classification. It classifies a data point based on its neighbors’ classifications. It stores all available cases and classifies new cases based on similar features.
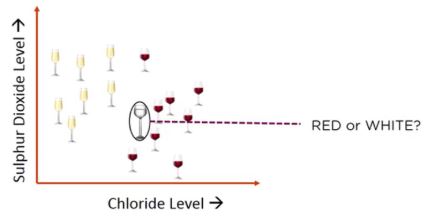
The following example below shows a KNN algorithm being leveraged to predict if a glass of wine is red or white. Different variables that are considered in this KNN algorithm include sulphur dioxide and chloride levels.
K in KNN is a parameter that refers to the number of nearest neighbors in the majority voting process.
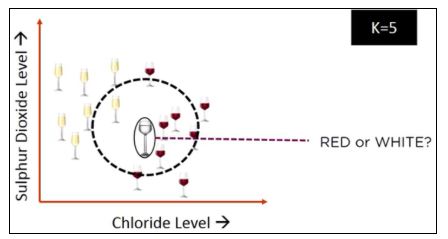
Here, we have taken K=5. The majority votes from its fifth nearest neighbor and classifies the data point. The glass of wine will be classified as red since four out of five neighbors are red.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
How to Choose the Factor ‘K’?
A KNN algorithm is based on feature similarity. Selecting the right K value is a process called parameter tuning, which is important to achieve higher accuracy.
There is not a definitive way to determine the best value of K. It depends on the type of problem you are solving, as well as the business scenario. The most preferred value for K is five. Selecting a K value of one or two can be noisy and may lead to outliers in the model, and thus resulting in overfitting of the model. The algorithm performs well on the training set, compared to its true performance on unseen test data.
Consider the following example below to predict which class the new data point belongs to.
If you take K=3, the new data point is a red square.
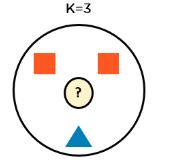
But, if we consider K=7, the new data point is a blue triangle. This is because the amount of red squares outnumbers the blue triangles.
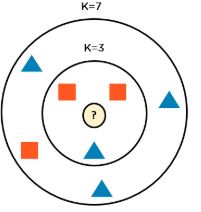
To choose the value of K, take the square root of n (sqrt(n)), where n is the total number of data points. Usually, an odd value of K is selected to avoid confusion between two classes of data.
When Do We Use the KNN Algorithm?
The KNN algorithm is used in the following scenarios:
- Data is labeled
- Data is noise-free
- Dataset is small, as KNN is a lazy learner
Become an AI and ML Expert in 2024
Discover the Power of AI and ML With UsEXPLORE NOW![]()
Pros and Cons of Using KNN
Pros:
- Since the KNN algorithm requires no training before making predictions, new data can be added seamlessly, which will not impact the accuracy of the algorithm.
- KNN is very easy to implement. There are only two parameters required to implement KNN—the value of K and the distance function (e.g. Euclidean, Manhattan, etc.)
Cons:
- The KNN algorithm does not work well with large datasets. The cost of calculating the distance between the new point and each existing point is huge, which degrades performance.
- Feature scaling (standardization and normalization) is required before applying the KNN algorithm to any dataset. Otherwise, KNN may generate wrong predictions.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
How Does a KNN Algorithm Work?
Consider a dataset that contains two variables: height (cm) & weight (kg). Each point is classified as normal or underweight.
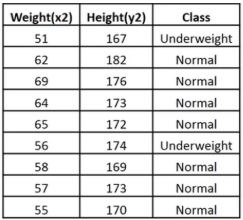
Based on the above data, you need to classify the following set as normal or underweight using the KNN algorithm.
To find the nearest neighbors, we will calculate the Euclidean distance.
The Euclidean distance between two points in the plane with coordinates (x,y) and (a,b) is given by:
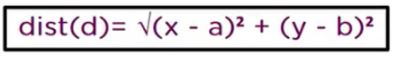
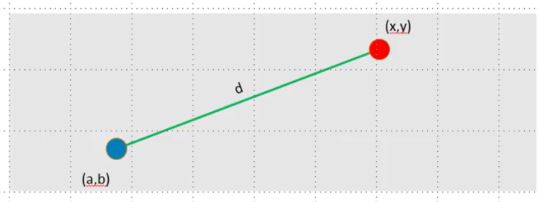
Let us calculate the Euclidean distance with the help of unknown data points.
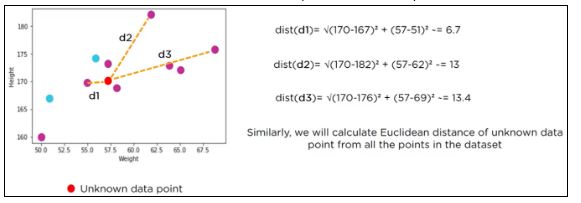
The following table shows the calculated Euclidean distance of unknown data points from all points.
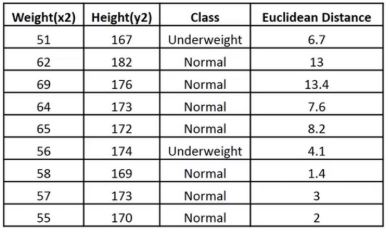
Now, we have a new data point (x1, y1), and we need to determine its class.

Looking at the new data, we can consider the last three rows from the table—K=3.
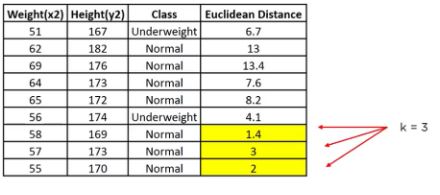
Since the majority of neighbors are classified as normal as per the KNN algorithm, the data point (57, 170) should be normal.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Use Case: Diabetes Prediction
The goal of this use case is to predict whether a person will be diagnosed with diabetes or not.
The dataset we’ll be using has information on 768 people who were diagnosed with diabetes and those who were not.
The following is what the dataset looks like:
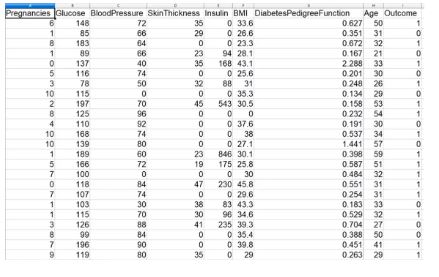
The dataset encompasses a wide range of features, such as pregnancies, glucose, blood pressure, skin thickness, insulin, BMI, diabetes pedigree function, age, and outcome (target variable).
Let’s start by installing the necessary libraries.
Load the dataset using pandas:
Certain columns, like glucose, blood pressure, insulin, and BMI, cannot contain values that are zeroes, as it will affect the outcome. We can replace such values with the mean of the respective columns.
Next, we will split the dataset into training and testing sets.

Rule of thumb: If an algorithm computes distance or assumes normality, scale your features.

Now, define the using KNeighborsClassifier to fit the training data into the model.
Predict the test set results.

Calculate the accuracy of the model.

The accuracy of our model is (94+32)/(94+13+32+15) = 0.81
You can also find the accuracy of the model using the accuracy_score function.
KNN Algorithm Uses in Real World
In the real world, the KNN algorithm has applications for both classification and regression problems.
KNN is widely used in almost all industries, such as healthcare, financial services, eCommerce, political campaigns, etc. Healthcare companies use the KNN algorithm to determine if a patient is susceptible to certain diseases and conditions. Financial institutions predict credit card ratings or qualify loan applications and the likelihood of default with the help of the KNN algorithm. Political analysts classify potential voters into separate classes based on whom they are likely to vote for.
Looking forward to becoming a Machine Learning Engineer? Check out Simplilearn’s AI and ML Course and get certified today.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program![]()
Conclusion
We hope that this guide helped to explain the basics of the KNN algorithm, and how it classifies data based on certain features. We also examined when it’s best to use the K value and when to use the KNN algorithm. Finally, we went through a use case demo to predict whether a person is likely to develop diabetes or not.
Ready to Learn More About Machine Learning?
If you are looking to kickstart your career in this exciting field, check out our AI ML Certification Courses today. You’ll get a solid foundation on how to leverage algorithms to make valuable and game changing predictions in any industry. What are you waiting for?






