


First-order principles of brain structure for AI assistants
![]()
Hello everyone, this article is a written form of a tutorial I conducted two weeks ago with Neurons Lab. If you prefer a narrative walkthrough, you can find the YouTube video here:
As always, you can find the code on GitHub, and here are separate Colab Notebooks:
- Planning and reasoning
- Different types of memories
- Various types of tools
- Building complete agents
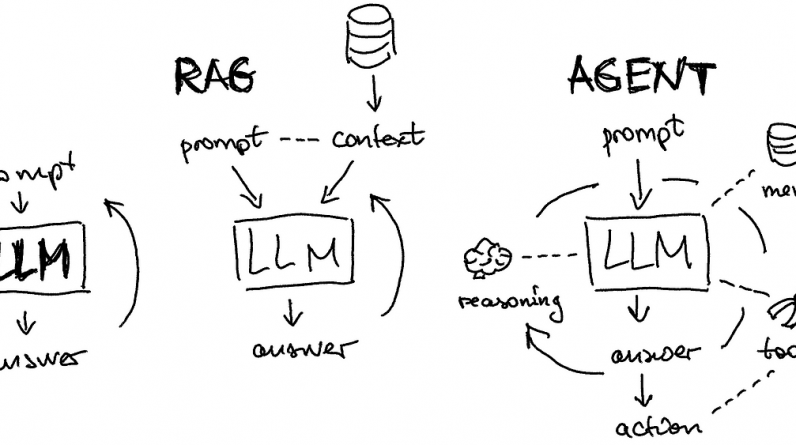
Illustration by author. LLMs are often augmented with external memory via RAG architecture. Agents extend this concept to memory, reasoning, tools, answers, and actions
Let’s begin the lecture by exploring various examples of LLM agents. While the topic is widely discussed, few are actively utilizing agents; often, what we perceive as agents are simply large language models. Let’s consider such a simple task as searching for football game results and saving them as a CSV file. We can compare several available tools:
- GPT-4 with search and plugins: as you will find in the chat history here, GPT-4 failed to do the task due to code errors
- AutoGPT through at least could generate some kind of CSV (not ideal though):
Since the available tools are not great, let’s learn from the first principles of how to build agents from scratch. I am using amazing Lilian’s blog article as a structure reference but adding more examples on my own.
The visual difference between simple “input-output” LLM usage and such techniques as a chain of thought, a chain of thought with self-consistency, a tree of thought
You might have come across various techniques aimed at improving the performance of large language models, such as offering tips or even jokingly threatening them. One popular technique is called “chain of thought,” where the model is asked to think step by step, enabling self-correction. This approach has evolved into more advanced versions like the “chain of thought with self-consistency” and the generalized “tree of thoughts,” where multiple thoughts are created, re-evaluated, and consolidated to provide an output.
In this tutorial, I am using heavily Langsmith, a platform for productionizing LLM applications. For example, while building the tree of thoughts prompts, I save my sub-prompts in the prompts repository and load them:
from langchain import hub
from langchain.chains import SequentialChain
cot_step1 = hub.pull(“rachnogstyle/nlw_jan24_cot_step1”)
cot_step2 = hub.pull(“rachnogstyle/nlw_jan24_cot_step2”)
cot_step3 = hub.pull(“rachnogstyle/nlw_jan24_cot_step3”)
cot_step4 = hub.pull(“rachnogstyle/nlw_jan24_cot_step4”)
model = “gpt-3.5-turbo”
chain1 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step1,
output_key=”solutions”
)
chain2 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step2,
output_key=”review”
)
chain3 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step3,
output_key=”deepen_thought_process”
)
chain4 = LLMChain(
llm=ChatOpenAI(temperature=0, model=model),
prompt=cot_step4,
output_key=”ranked_solutions”
)
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=[“input”, “perfect_factors”],
output_variables=[“ranked_solutions”],
verbose=True
)
You can see in this notebook the result of such reasoning, the point I want to make here is the right process for defining your reasoning steps and versioning them in such an LLMOps system like Langsmith. Also, you can see other examples of popular reasoning techniques in public repositories like ReAct or Self-ask with search:
prompt = hub.pull(“hwchase17/react”)
prompt = hub.pull(“hwchase17/self-ask-with-search”)
Other notable approaches are:
- Reflexion (Shinn & Labash 2023) is a framework to equip agents with dynamic memory and self-reflection capabilities to improve reasoning skills.
- Chain of Hindsight (CoH; Liu et al. 2023) encourages the model to improve on its own outputs by explicitly presenting it with a sequence of past outputs, each annotated with feedback.
We can map different types of memories in our brain to the components of the LLM agents’ architecture
- Sensory Memory: This component of memory captures immediate sensory inputs, like what we see, hear or feel. In the context of prompt engineering and AI models, a prompt serves as a transient input, similar to a momentary touch or sensation. It’s the initial stimulus that triggers the model’s processing.
- Short-Term Memory: Short-term memory holds information temporarily, typically related to the ongoing task or conversation. In prompt engineering, this equates to retaining the recent chat history. This memory enables the agent to maintain context and coherence throughout the interaction, ensuring that responses align with the current dialogue. In code, you typically add it as conversation history:
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.agents import AgentExecutor
from langchain.agents import create_openai_functions_agent
llm = ChatOpenAI(model=”gpt-3.5-turbo”, temperature=0)
tools = [retriever_tool]
agent = create_openai_functions_agent(
llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key=”input”,
history_messages_key=”chat_history”,
)
- Long-Term Memory: Long-term memory stores both factual knowledge and procedural instructions. In AI models, this is represented by the data used for training and fine-tuning. Additionally, long-term memory supports the operation of RAG frameworks, allowing agents to access and integrate learned information into their responses. It’s like the comprehensive knowledge repository that agents draw upon to generate informed and relevant outputs. In code, you typically add it as a vectorized database:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader(“https://neurons-lab.com/”)
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
In practice, you want to augment your agent with a separate line of reasoning (which can be another LLM, i.e. domain-specific or another ML model for image classification) or with something more rule-based or API-based
ChatGPT Plugins and OpenAI API function calling are good examples of LLMs augmented with tool use capability working in practice.
- Built-in Langchain tools: Langchain has a pleiad of built-in tools ranging from internet search and Arxiv toolkit to Zapier and Yahoo Finance. For this simple tutorial, we will experiment with the internet search provided by Tavily:
from langchain.utilities.tavily_search import TavilySearchAPIWrapper
from langchain.tools.tavily_search import TavilySearchResults
search = TavilySearchAPIWrapper()
tavily_tool = TavilySearchResults(api_wrapper=search)
llm = ChatOpenAI(model_name=”gpt-3.5-turbo”, temperature=0.0)
agent_chain = initialize_agent(
[retriever_tool, tavily_tool],
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
- Custom tools: it’s also very easy to define your own tools. Let’s dissect the simple example of a tool that calculates the length of the string. You need to use the @tooldecorator to make Langchain know about it. Then, don’t forget about the type of input and the output. But the most important part will be the function comment between “”” “”” — this is how your agent will know what this tool does and will compare this description to descriptions of the other tools:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
@tool
def calculate_length_tool(a: str) -> int:
“””The function calculates the length of the input string.”””
return len(a)
llm = ChatOpenAI(model_name=”gpt-3.5-turbo”, temperature=0.0)
agent_chain = initialize_agent(
[retriever_tool, tavily_tool, calculate_length_tool],
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
You can find examples of how it works in this script, but you also can see an error — it doesn’t pull the correct description of the Neurons Lab company and despite calling the right custom function of length calculation, the final result is wrong. Let’s try to fix it!
I am providing a clean version of combining all the pieces of architecture together in this script. Notice, how we can easily decompose and define separately:
- All kinds of tools (search, custom tools, etc)
- All kinds of memories (sensory as a prompt, short-term as runnable message history, and as a sketchpad within the prompt, and long-term as a retrieval from the vector database)
- Any kind of planning strategy (as a part of a prompt pulled from the LLMOps system)
The final definition of the agent will look as simple as this:
llm = ChatOpenAI(model=”gpt-3.5-turbo”, temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key=”input”,
history_messages_key=”chat_history”,
)
As you can see in the outputs of the script (or you can run it yourself), it solves the issue in the previous part related to tools. What changed? We defined a complete architecture, where short-term memory plays a crucial role. Our agent obtained message history and a sketchpad as a part of the reasoning structure which allowed it to pull the correct website description and calculate its length.
I hope this walkthrough through the core elements of the LLM agent architecture will help you design functional bots for the cognitive tasks you aim to automate. To complete, I would like to emphasize again the importance of having all elements of the agent in place. As we can see, missing short-term memory or having an incomplete description of a tool can mess with the agent’s reasoning and provide incorrect answers even for very simple tasks like summary generation and its length calculation. Good luck with your AI projects and don’t hesitate to reach out if you need help at your company!






