


AI systems like Bing and Microsoft Copilot (web) are as good as they are because they continuously learn and improve from peopleâs interactions. Since the early 2000s, user clicks on search result pages have fueled the continuous improvements of search engines. Recently, reinforcement learning from human feedback (RLHF) brought step-function improvements to response quality of generative AI models. Bing has a rich history of success in improving its AI offerings by learning from user interactions. For example, Bing pioneered the idea of improving search ranking (opens in new tab) and personalizing search (opens in new tab) using short- and long-term user behavior data (opens in new tab).
With the introduction of Microsoft Copilot (web), the way that people interact with AI systems has fundamentally changed from searching to conversing and from simple actions to complex workflows. Today, we are excited to share three technical reports on how we are starting to leverage new types of user interactions to understand and improve Copilot (web) for our consumer customers. [1]
How are people using Copilot (web)?
One of the first questions we asked about user interactions with Copilot (web) was, âHow are people using Copilot (web)?â Generative AI can perform many tasks that were not possible in the past, and itâs important to understand peopleâs expectations and needs so that we can continuously improve Copilot (web) in the ways that will help users the most.
Spotlight: On-demand video
AI Explainer: Foundation models âand the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
A key challenge of understanding user tasks at scale is to transform unstructured interaction data (e.g., Copilot logs) into a meaningful task taxonomy. Existing methods heavily rely on manual effort, which is not scalable in novel and under-specified domains like generative AI. To address this challenge, we introduce TnT-LLM (Taxonomy Generation and Text Prediction with LLMs), a two-phase LLM-powered framework that generates and predicts task labels end-to-end with minimal human involvement (Figure 1).
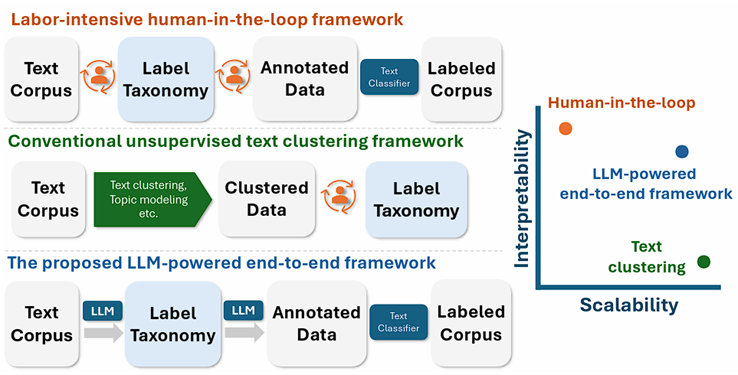 Figure 1. Comparing our TnT-LLM framework against existing methods in terms of interpretability and scalability.
Figure 1. Comparing our TnT-LLM framework against existing methods in terms of interpretability and scalability.
We conducted extensive human evaluation to understand how TnT-LLM performs. In discovering user intent and domain from Copilot (web) conversations, taxonomies generated by TnT-LLM are significantly more accurate than existing baselines (Figure 2).
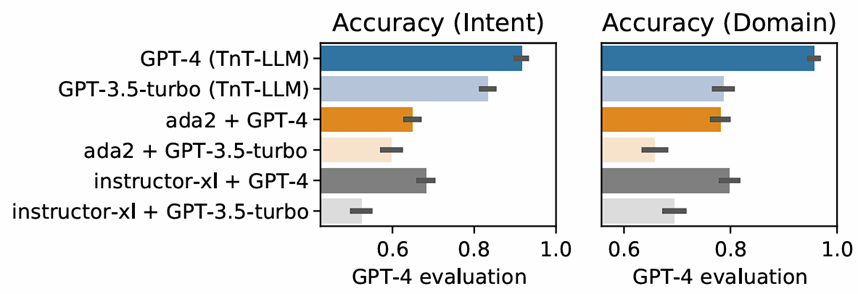 Figure 2. Evaluating the performance of TnT-LLM on user intent taxonomy generation. Error bars indicate 95% confidence intervals.
Figure 2. Evaluating the performance of TnT-LLM on user intent taxonomy generation. Error bars indicate 95% confidence intervals.
We applied TnT-LLM to a large-scale number of fully de-identified Copilot (web) conversations and traditional Bing Search sessions. The results (Figure 3) suggest that people use Copilot (web) for knowledge work tasks in domains such as writing and editing, data analysis, programming, science, and business. Further, tasks done in Copilot (web) generally are of higher complexity and more knowledge work-oriented compared to tasks done in traditional search engines. Generative AI’s emerging capabilities have evolved the tasks that machines can perform, to include some that humans have traditionally had to do without assistance. Results demonstrate that people are doing more complex tasks, frequently in the context of knowledge work, and show that this type of work is being newly assisted by Copilot (web).
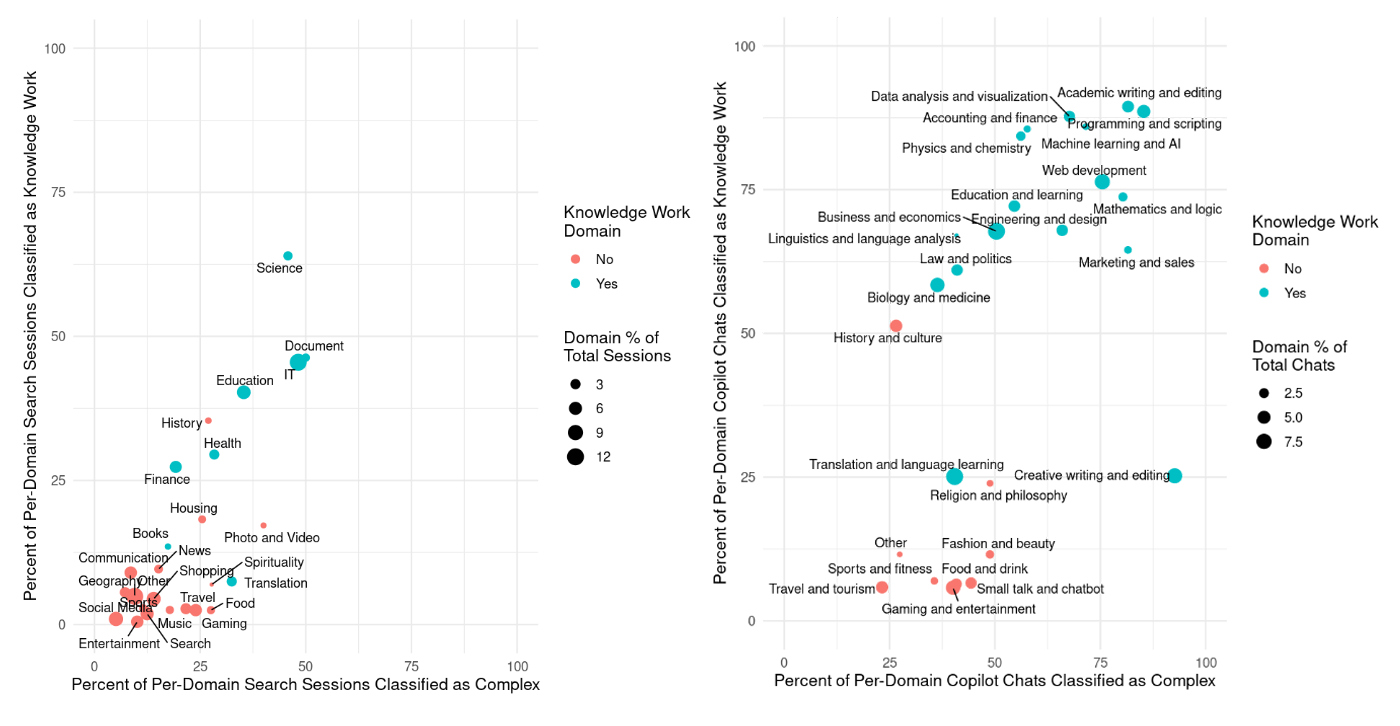 Figure 3. Comparing the distribution of topical domains and task complexity between Bing search (left) and Copilot (web) (right).
Figure 3. Comparing the distribution of topical domains and task complexity between Bing search (left) and Copilot (web) (right).
Estimating and interpreting user satisfaction
To effectively learn from user interactions, it is equally important to classify user satisfaction and to understand why people are satisfied or dissatisfied while trying to complete a given task. Most important, this will allow system developers to identify areas of improvement and to amplify and suggest successful use cases for broader groups of users.
People give explicit and implicit feedback when interacting with AI systems. In the past, user feedback was in the form of clicks, ratings, or survey verbatims. When it comes to conversational systems like Copilot (web), people also give feedback in the messages they send during the conversations (Figure 4).
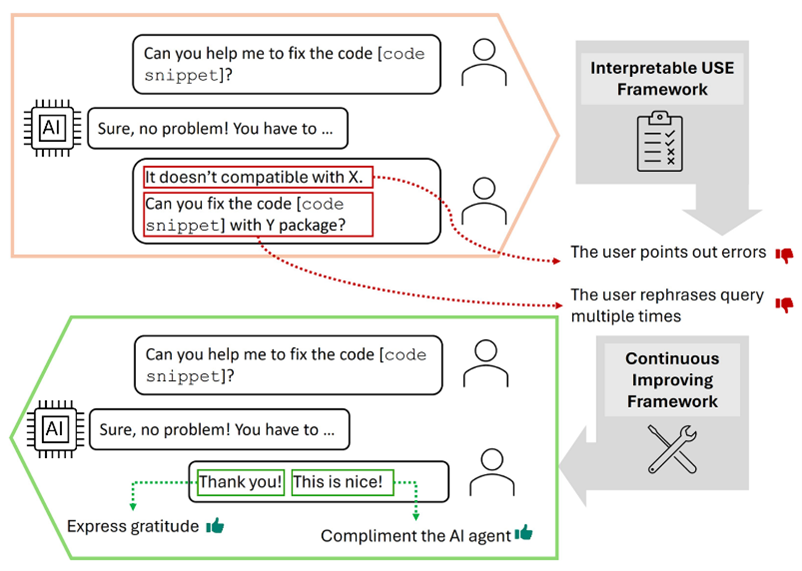 Figure 4. Illustrations of how people may give feedback to a chatbot in their messages.
Figure 4. Illustrations of how people may give feedback to a chatbot in their messages.
To capture this new category of feedback signals, we propose our Supervised Prompting for User Satisfaction Rubrics (SPUR) (opens in new tab) framework (Figure 5). Itâs a three-phase prompting framework for estimating user satisfaction with LLMs:
- The supervised extraction prompt extracts diverse in situ textual feedback from users interacting with Copilot (web).
- The summarization rubric prompt identifies prominent textual feedback patterns and summarizes them into rubrics for estimating user satisfaction.
- Based on the summarized rubrics, the final scoring prompt takes a conversation between a user and the AI agent and rates how satisfied the user was.
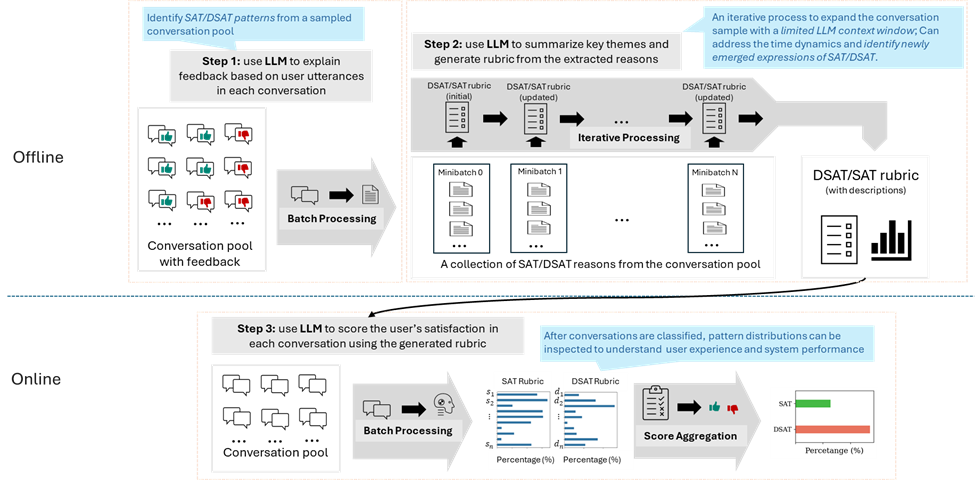 Figure 5. Framework of Supervised Prompting for User Satisfaction Rubrics.
Figure 5. Framework of Supervised Prompting for User Satisfaction Rubrics.
We evaluated our framework on fully de-identified conversations with explicit user thumbs up/down in Copilot (web) (Table 1). We find that SPUR outperforms other LLM-based and embedding-based methods, especially only limited human annotations of user satisfaction are available. Open-source reward models used for RLHF cannot be a proxy for user satisfaction, because reward models are usually trained with auxiliary human feedback that may differ from the feedback from the user who was involved in the conversation with the AI agent.
| Method | Weighted F1-score |
|---|---|
| Reward (RLHF) | 17.8 |
| ASAP (SOTA of embedding) | 57.0 |
| Zero-Shot (GPT4) | 74.1 |
| SESRP (GPT4) | 77.4 |
Table 1. Performance comparison between models for user satisfaction estimation.
Another critical feature of SPUR is its interpretability. It shows how people express satisfaction or dissatisfaction (Figure 6). For example, we see that users often give explicit positive feedback by clearly praising the response from Copilot (web). Conversely, they express explicit frustration or switch topics when encountering mistakes in the response from Copilot (web). This presents opportunities for providing customized user experience at critical moments of user satisfaction and dissatisfaction, such as context and memory reset after switching topics.
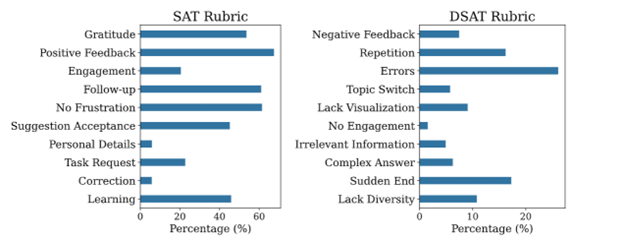 Figure 6. SPUR reveals the distribution of satisfaction and dissatisfaction patterns among conversations with explicit user upvotes or downvotes.
Figure 6. SPUR reveals the distribution of satisfaction and dissatisfaction patterns among conversations with explicit user upvotes or downvotes.
In the user task classification discussed earlier, we know that people are using Copilot (web) for knowledge work and more complex tasks. As we further apply SPUR for user satisfaction estimation, we find that people are also more satisfied when they complete or partially complete cognitively complex tasks. Specifically, when regressing task complexity on the SPUR-derived summary user-satisfaction score, we find generally increasing coefficients on increasing levels of task complexity when using the lowest level of task complexity (i.e. Remember) as a baseline, provided the task was at least partially completed (see Table 2). For instance, partially completing a Create-level task, which is the highest level of task complexity, leads to an increase in user satisfaction that is more than double the increase when partially completing an Understand-level task. Fully completing a Create-level task leads to the largest increase in user satisfaction.
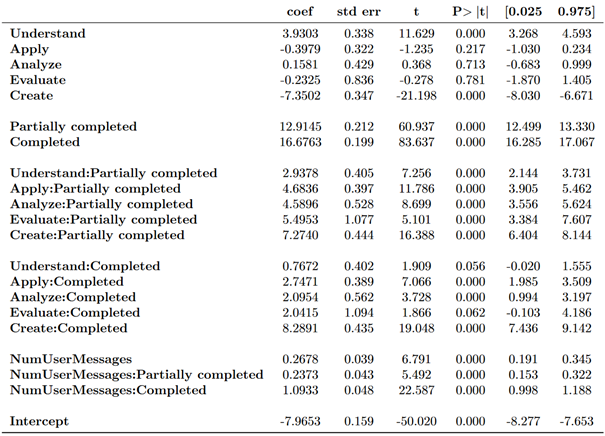 Table 2. Regression results where the dependent variable is user satisfaction. In general, the more complex the task, the more satisfied the user whether it was partially or totally completed.
Table 2. Regression results where the dependent variable is user satisfaction. In general, the more complex the task, the more satisfied the user whether it was partially or totally completed.
These three reports present a comprehensive and multi-faceted approach to dynamically learning from conversation logs in Copilot (web) at scale. As AIâs generative capabilities increase, users are finding new ways to use the system to help them do more and shift from traditional click reactions to more nuanced, continuous dialogue-oriented feedback. To navigate this evolving user-AI interaction landscape, it is crucial to shift from established task frameworks and relevance evaluations to a more dynamic, bottom-up approach to task identification and user satisfaction evaluation.
Key Contributors
Reid Andersen, Georg Buscher, Scott Counts, Deepak Gupta, Brent Hecht, Dhruv Joshi, Sujay Kumar Jauhar, Ying-Chun Lin, Sathish Manivannan, Jennifer Neville, Nagu Rangan, Chirag Shah, Dolly Sobhani, Siddharth Suri, Tara Safavi, Jaime Teevan, Saurabh Tiwary, Mengting Wan, Ryen W. White, Xia Song, Jack W. Stokes, Xiaofeng Xu, and Longqi Yang.
[1] The research was performed only on fully de-identified interaction data from Copilot (web) consumers. No enterprise data was used per our commitment to enterprise customers. We have taken careful steps to protect user privacy and adhere to strict ethical and responsible AI standards. All personal, private or sensitive information was scrubbed and masked before conversations were used for the research. The access to the dataset is strictly limited to approved researchers. The study was reviewed and approved by our institutional review board (IRB).
