A significant number of supervised learning techniques have been developed in the machine learning industry over the past ten years. A large chunk of machine learning research has focused on supervised learning. Numerous supervised learning approaches have found use in the processing and analysis of various types of data. The capacity of supervised learning to use labeled training data is one of its key qualities. The supervised learning techniques utilize a wide range of algorithms. This article provides an overview of supervised learning core components.
Before going deep into supervised learning, let’s take a short tour of What is machine learning.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
What Is Machine Learning?
Machine learning is the art of making computers learn and act like humans by feeding data. It focuses on utilizing information and imitating how people learn, step by step, working on its accuracy.
Machine learning is becoming more and more important in our daily lives. Identification of trends and patterns, automation, predicting of the weather, predictive analysis, and many other applications utilize machine learning.
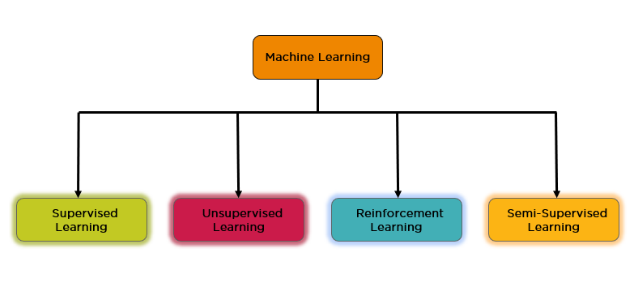
Machine learning is classified into –
What Is Supervised Machine Learning?
In supervised learning, machines are trained using labeled data, also known as training data, to predict results. Data that has been tagged with one or more names and is already familiar to the computer is called “labeled data.”
Some real-world examples of supervised learning include Image and object recognition, predictive analytics, customer sentiment analysis, spam detection, and many more.
Become an AI and ML Expert in 2024
Discover the Power of AI and ML With UsEXPLORE NOW![]()
How Supervised Machine Learning Works?
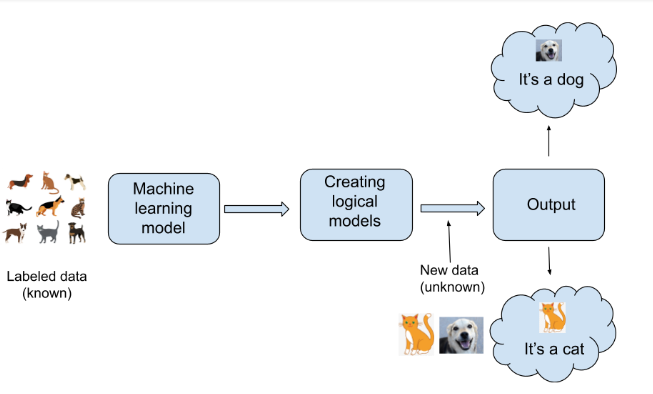
Supervised learning models are trained using labeled data, also known as training data, to predict results.
Consider we have a dataset with data on both cats and dogs. Each dog and cat model must first be trained using similarity, pattern, shape, and contrast criteria.
The model’s main function is to recognize the new input data when evaluated using a new input data set that was not used for the subsequent training.
The computer is trained to recognize all kinds of patterns, forms, and contrasts. Additionally, it categorizes newly discovered data based on similarities, patterns, form, and contrast and forecasts the correct output.
Advantages of Supervised Machine Learning
- Supervised learning resolves various computation issues encountered in the real world, including spam detection, object and image identification, and many more.
- Supervised learning uses past experience to optimize performance and predict the outputs based on past experiences.
- The training data can be reused unless there is any feature change.
Join the Ranks of AI Innovators
UT Dallas AI and Machine Learning BootcampEXPLORE PROGRAM![]()
Disadvantages of Supervised Machine Learning
- Computation time, or running time, is huge for supervised learning.
- Supervised learning models frequently need updates.
- Pre-processing of data is a big challenge for predicting the output.
- Anyone can overfit supervised algorithms easily. It happens when a statistical model matches its training data.
Types of Supervised Machine Learning
Supervised learning can be further classified into two problems which are:
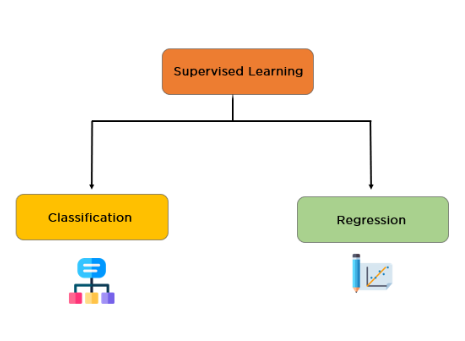
Classification
Classification is a process in which new observations are recognized and separated to categorize them.
You can classify something based on its traits if you consider it a group of items, such as a collection of vegetables. For example, you could classify the potatoes, tomatoes, and peppers into A, B, and C categories.
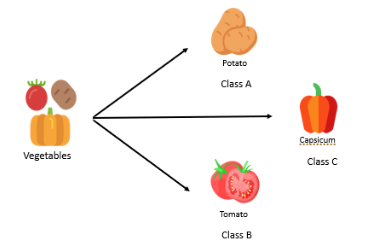
These are some popular classification algorithms that come under supervised learning:
- Random Forest
- Decision Trees
- Logistic Regression
- Support Vector Machines
Become an Artificial Intelligence Innovator
Kick-start Your AI & ML Career with UsStart Learning![]()
Regression
A regression algorithm is used to figure out the connection between dependent and independent variables. Dependent variables are responsible for predicting and forecasting. And independent variables are those which affect the analysis.
It is usually used to make projections. Consider we have variable one as humidity and variable two as the temperature, where the temperature will be the independent variable and humidity will act as the dependent variable. Humidity and temperature are correlated as temperature increases, humidity decreases, and vice versa.

Organizations majorly used the regression model for the prediction of stocks. This is done by breaking down past information on stock costs and trends to recognize patterns.
Some popular regression algorithms in supervised learning:
Caltech AI & Machine Learning Bootcamp
Advance Your AI & ML Career With Our BootcampEnroll Now![]()
Supervised Machine Learning Algorithms
This article will discuss the top 9 machine learning algorithms for supervised learning problems, including Linear regression, Regression trees, Non-linear regression, Bayesian linear regression, logistic regression, decision tree, random forest, and support vector machine.
- Linear Regression: When making predictions about future outcomes, linear regression is frequently used to identify the relationship between a dependent variable and at least one independent variable.
Companies frequently use linear regression models to forecast future sales. This is useful for planning and arranging. Algorithms like Amazon’s product-to-product collaborative filtering are utilized to predict what clients will purchase later, given their past purchase history.
- Regression Trees: Regression trees are built via binary recursive partitioning, an iterative interaction that splits the data into segments or branches.
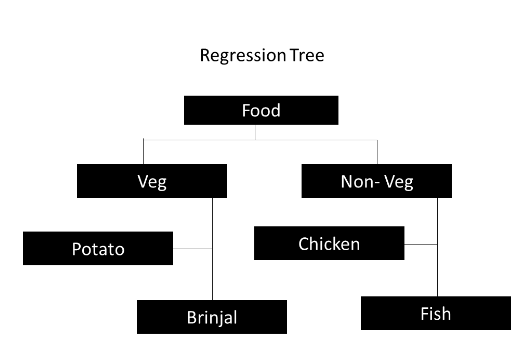
As it advances up each branch, the method subsequently separates each data set into smaller groups. When the dependent variable has continuous values, such as when splitting the food segment of a regression model tree into vegetarian and non-vegetarian portions, it keeps dispersing into smaller groups.
- Non-Linear Regression: Nonlinear regression involves fitting data to a model and then communicating the results as a numerical function. Simple linear regression establishes a straight line relationship between two factors (X and Y) (y = mx + b),

whereas nonlinear regression establishes a nonlinear relationship between the two factors. The prediction of population increase over time or the relationship between a nation’s GDP and time can both be done using nonlinear regression.
- Bayesian Linear Regression: With the help of Bayesian inference, the Bayesian Linear Regression attempts to handle linear regression while also conducting a statistical analysis
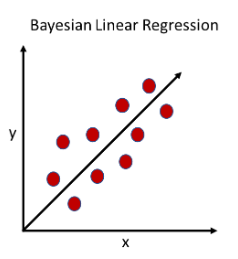
The predictions produced by linear regression and Bayesian regression are comparable. Additionally, we can recover the entire range of explanatory solutions rather than simply extracting a prediction equation using Bayesian processing.
- Random Forest: The term “Random Forest” refers to a collection of decision trees. Each tree is assigned a class, and the tree “votes” for that class to categorize a new item based on its characteristics. The classification with the highest votes is selected by the forest (over all the trees in the forest).

Researchers use Random Forest at work in various enterprises, including banking, stock trading, medicine, and internet commerce. It forecasts factors like customer behavior, patient demographics, and safety that help these firms run efficiently.
Caltech AI & Machine Learning Bootcamp
Advance Your AI & ML Career With Our BootcampEnroll Now![]()
- Decision Trees: A decision tree is a unique type of tree that provides the capability to draw conclusions regarding a method used for a dependent variable with discrete values.

Consider, you have to decide whether to invest resources in decision 1, decision 2, or decision 3, or whether to manufacture products A or B. Decision trees are a fantastic tool for handling these kinds of difficult decisions.
- Logistic Regression: A set of independent variables estimates discrete values (often binary values like 0/1) using logistic regression. Fitting data to a logistic regression function helps predict an event’s probability.

For example, logistic regression can be used to predict whether a political candidate will win or lose and whether or not a secondary school student would be admitted to a given secondary school.
- Support Vector Machine: The support vector machine (SVM) is used for information regression and classification. In light of everything, it is usually used for grouping issues. Like It can be compatible with filters.

The filter will be added below the expression if we carry out specific looks. Between happy and sad are the possible expressions.
Applications of Supervised Machine Learning
Several commercial applications can be developed using supervised learning models, including the ones listed below:
- Image and object recognition: Supervised learning algorithms can be Utilized to find, isolate, and sort objects from videos or pictures. It makes them valuable when applied to different computer vision strategies and imagery analysis.
- Predictive analysis: A broad use case for supervised learning models is in making predictive analytics systems to give profound experiences into different business data of interest. This permits endeavors to expect specific outcomes because of a given result variable, assisting business leaders to justify choices or turn to serve the association.
- Customer Sentiment Analysis: Supervised learning algorithms, and associations, can extract and arrange significant pieces of data from huge volumes of information — including context, emotion, and purpose — with very little human intervention. This can be incredibly valuable while acquiring a superior understanding of client collaborations and can be utilized to further develop brand engagement efforts.
- Spam Detection: Companies can create data sets using classification techniques to identify trends or anomalies in new information and separate spam and non-spam-related correspondences.
Stay ahead of the tech-game with our AI ML Certification in partnership with Purdue and in collaboration with IBM. Explore more!
Become an Artificial Intelligence Innovator
Kick-start Your AI & ML Career with UsStart Learning![]()
Conclusion
Supervised learning focuses on constructing a machine learning model that can familiarize the planning between the data and the result, thereby predicting the output of the given new data sources. It is the most specific subcategory of machine learning. It is the most generally utilized type of machine learning and has shown to be an excellent tool in many industries.
If you are looking to further enhance your skills, you can check Simplilearn’s Machine Learning Course. This course will help you hone the key skills and make you job ready.
Do you have any questions for us? Please mention it in the comment section of the “Supervised Machine Learning All You Need to Know” article, and we’ll have our experts answer it for you.