How do we know if our model is functional? If we have trained it well? All of this can be determined by seeing how our model performs on previously unseen data, data that is completely new to it. We need to ensure that the accuracy of our model remains constant throughout. In other words, we need to validate our model.
Using cross-validation in machine learning, we can determine how our model is performing on previously unseen data and test its accuracy.
Join the Ranks of AI Innovators
UT Dallas AI and Machine Learning BootcampEXPLORE PROGRAM
Why Do Models Lose Stability?
Any machine learning model needs to consistently predict the correct output across a variation of different input values, present in different datasets. This characteristic of a machine learning model is called stability. If a model does not change much when the input data is modified, it means that it has been trained well to generalize and find patterns in our data. A model can lose stability in two ways:
- Underfitting: It occurs when the model does not fit properly to training data. It does not find patterns in the data and hence when it is given new data to predict, it cannot find patterns in it too. It under-performs on both known and unseen data.
- Overfitting: When the model trains well on training data and generalizes to it, but fails to perform on new, unseen data. It captures every little variation in training data and cannot perform on data that does not have the same variations.
The figures depicted below show unfit, overfit, and optimally fit models:
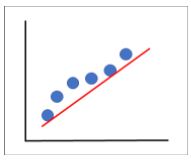
Figure 1: Underfitting
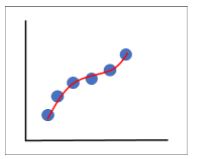
Figure 2: Overfitting
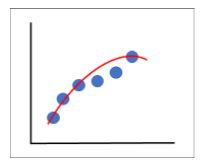
Figure 3: Optimal Model
In Figure 1, we can see that the model does not quite capture all the features of our data and leaves out some important data points. This model has generalized our data too much and is under fitted. In Figure 2, our model has captured every single aspect of the data, including the noise. If we were to give it a different dataset, it would not be able to predict it as it is too specific to our training data, hence it is overfitted. In figure 3, the model captures the intricacies of our model while ignoring the noise, this model is our optimal model.
What is Cross-Validation?
While choosing machine learning models, we need to compare models to see how different models perform on our dataset and to choose the best model for our data. However, data is usually limited, our dataset might not have enough data points or may even have missing or wrong data. Further, if we have fewer data, training, and testing on the same portion of data does not give us an accurate view of how our model performs. Training a model on the same data means that the model will eventually learn well for only that data and fail on new data, this is called overfitting. This is where cross-validation comes into the picture.
Cross-Validation in machine learning is a technique that is used to train and evaluate our model on a portion of our database, before re-portioning our dataset and evaluating it on the new portions.
This means that instead of splitting our dataset into two parts, one to train on and another to test on, we split our dataset into multiple portions, train on some of these and use the rest to test on. We then use a different portion to train and test our model on. This ensures that our model is training and testing on new data at every new step.
This also exposes our model to minority classes which may be present in the data. If we split our data into two and train only on one part, there is a chance that the test data contains a minority class that was not present in the testing data. In this case, our model will still perform well as the class constitutes only a small portion of the dataset but it will be desensitized to that data.
Consider the block below to represent the entirety of our data. We partition the dataset into training and testing data. The training data will be used by our model to learn. The testing dataset will be used by our model to predict unseen data. It is used to evaluate our model’s performance.
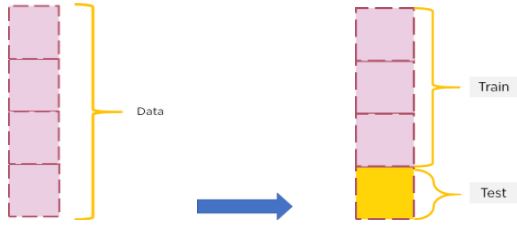
Figure 4: Partitioning dataset for cross-validation
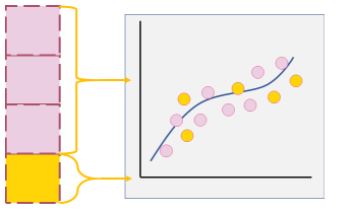
Figure 5: Training and testing with our portioned dataset
We then choose a different portion to test on and use the other portions for training. Then, the model performance is re-evaluated with the results obtained from the new portioned dataset to get better results.
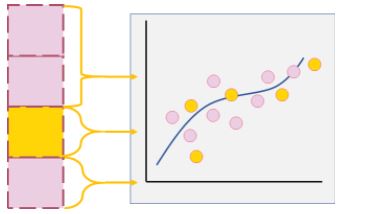
Figure 6: Training and testing on new portions
Steps in Cross-Validation
Step 1: Split the data into train and test sets and evaluate the model’s performance
The first step involves partitioning our dataset and evaluating the partitions. The output measure of accuracy obtained on the first partitioning is noted.
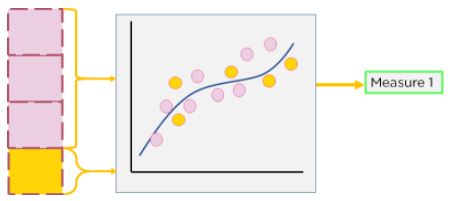
Figure 7: Step 1 of cross-validation partitioning of the dataset
Join the Ranks of AI Innovators
UT Dallas AI and Machine Learning BootcampEXPLORE PROGRAM![]()
Step 2: Split the data into new train and test sets and re-evaluate the model’s performance
After evaluating one portion of the dataset, we choose a different portion to test and train on. The output measure obtained from this new training and testing dataset is again noted.
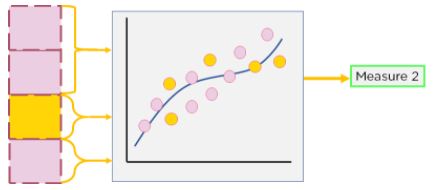
Figure 8: Step 2 of cross-validation revaluation on new portions
This step is repeated multiple times until the model has been trained and evaluated on the entire dataset.
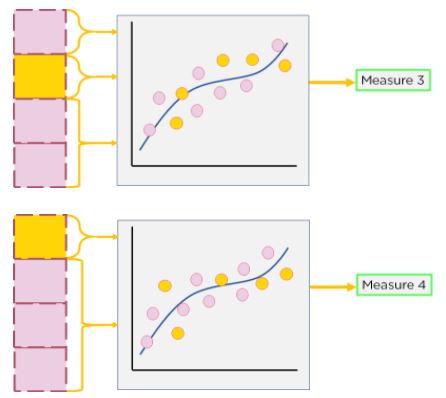
Figure 9: Repeating Step 2 of cross-validation
Step 3: To get the actual performance metric the average of all measures is taken
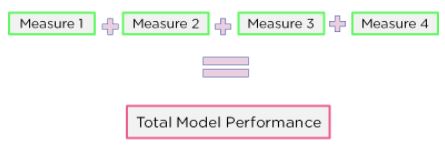
Figure 10: Step 3 of cross-validation getting model performance
Cross-Validation Models
There are various ways to perform cross-validation. Some of the commonly used models are:
- K-fold cross-validation: In K-fold cross-validation, K refers to the number of portions the dataset is divided into. K is selected based on the size of the dataset.
The dataset is split into k portions one section is for testing and the rest for training.
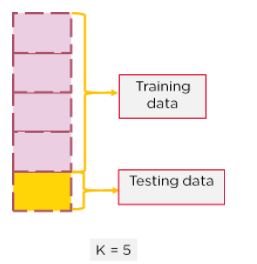
Figure 11: K-Fold with k = 5
Another section will be chosen for testing and the remaining section will be for training. This will continue K number of times until all sections have been used as a testing set once.
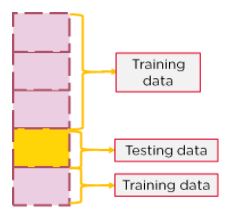
Figure 12: Selecting a different dataset portion for K-Fold CV
The final performance measure will be the average of the output measures of the K iterations

Figure 13: Final accuracy using K-fold
- Leave one out cross-validation (LOOCV): In LOOCV, instead of leaving out a portion of the dataset as testing data, we select one data point as the test data. The rest of the dataset will be used for training and the single data point will be used to predict after training.
Consider a dataset with N points. N-1 will be the training set and 1 point will be the testing set.
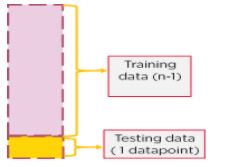
Figure 14: Splitting a dataset for LOOCV
Another point will be chosen as the testing data and the rest of the points will be training.
This will repeat for the rest of the dataset, i.e.: N times.
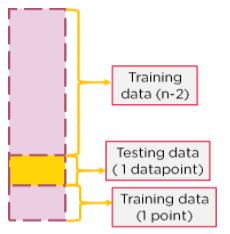
Figure 15: Selecting another point a testing data
The final performance measure will be the average of the measures for all n iterations.
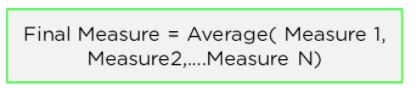
Figure 16: Performance measure for LOOCV
- Stratified K-fold cross-validation: This method is useful when there are minority classes present in our data. In some cases, while partitioning the data, some testing sets will include instances of minority classes while others will not. When this happens, our accuracy will not properly reflect how well minority classes are being predicted. To overcome this, The data is split so that each portion has the same percentage of all the different classes that exist in the dataset. Consider a dataset that has 2 classes of data as shown below.
Figure 17: Data with two classes present
In normal cross-validation, the data is divided without keeping in mind the distribution of individual classes. The model, thus cannot properly predict for minority classes.
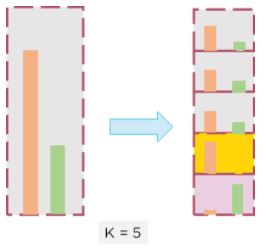
Figure 18: Division of data in cross-validation
Stratified K-folds overcomes this by maintaining the same percentage of data classes in all the folds, the model can be trained even on minority classes
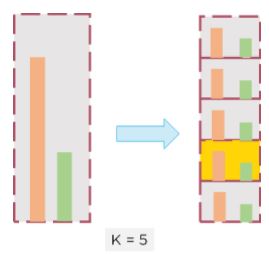
Figure 19: Division of data in Stratified K-Fold cross-validation
Join the Ranks of AI Innovators
UT Dallas AI and Machine Learning BootcampEXPLORE PROGRAM![]()
Cross-Validation With Python
Let’s look at cross-validation using Python. We will be using the adult income dataset to classify people based on whether their income is above $50k or not. We will be using Linear Regression and K Nearest Neighbours classifiers and using cross-validation, we will see which one performs better.
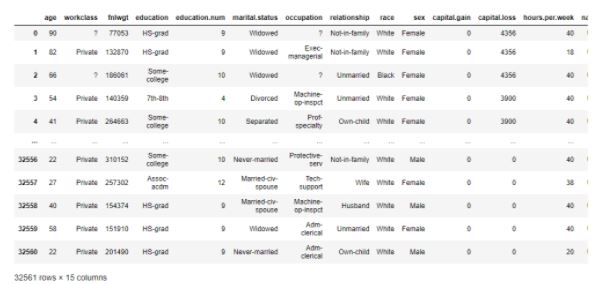
Figure 20: Adult Census Data
Importing the libraries necessary for our model:

Figure 21: Importing libraries
We have imported cross-validation module cross_val_score along with StratifiedKFold and KFold cross-validation modules.
As we can see, in our prediction class, the income is in words. Let us convert it into numeric form to make classification easier.

Figure 22: Formatting prediction class
Let us do the same with the sex column. At the same time, these are a bunch of relationships and marital status which can be simply converted into married or unmarried and then converted into binary classes.
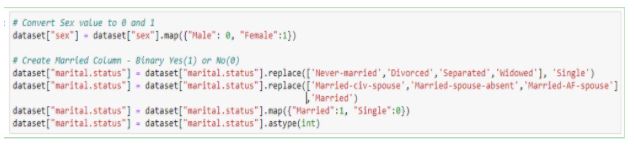
Figure 23: Formatting columns
After dropping unnecessary columns, the dataset will be significantly reduced.
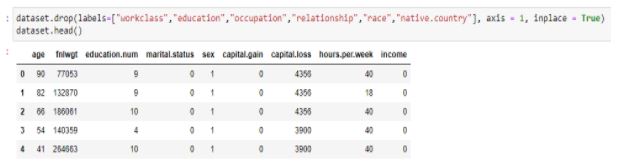
Figure 24: Dropping columns and the final dataset
Let us drop the income prediction class. Hence, our training dataset becomes :
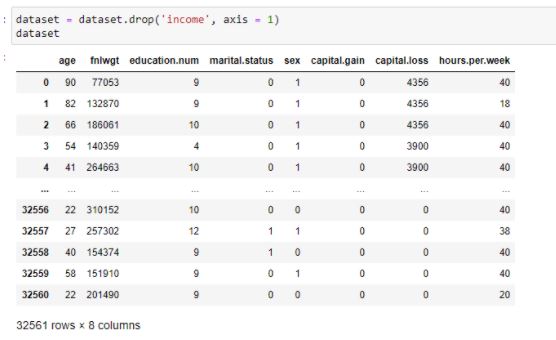
Figure 25: Training Dataset
Splitting the dataset into training and testing data and creating our models.
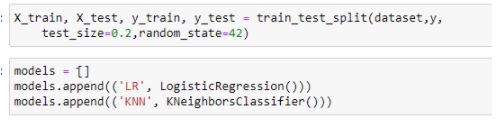
Figure 25: Splitting our dataset and creating models
Let us perform cross-validation, first using K-Fold Cross-Validation. We have taken k as 10. We can see that linear regression performs better.
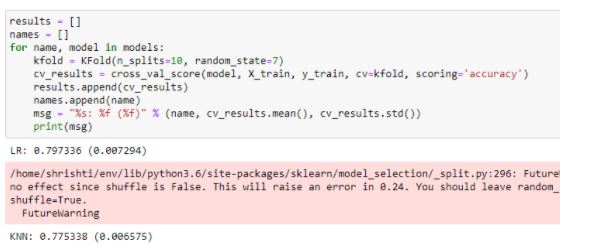
Figure 27: K-Fold Cross-Validation
Now, let’s use Stratified K-Fold and see the results.

Figure 28: Stratified K-Fold
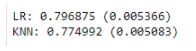
Figure 29: Results of Stratified K-Fold
Acelerate your career in AI and ML with the AI ML Course with Purdue University collaborated with IBM.
Master Generative AI in 2024
Transform Your Ideas Into RealityACCESS FREE![]()
Conclusion
In this article – The Ultimate Guide to Cross-Validation, we have looked at what causes model instability and what cross-validation is. We looked at the steps to perform cross-validation and the various cross-validation models which are commonly used. Finally, we got hands-on training on how cross-validation can be implemented in python.
Was this article on cross-validation useful to you? Do you have any doubts or questions for us? Mention them in this article’s comments section, and we’ll have our experts answer them for you at the earliest.
Looking forward to becoming a Machine Learning Engineer? Check out Simplilearn’s Machine Learning Course and get certified today.