


Welcome insideBIGDATA AI News Briefs Bulletin Board, our timely new feature bringing you the latest industry insights and perspectives surrounding the field of AI including deep learning, large language models, generative AI, and transformers. We’re working tirelessly to dig up the most timely and curious tidbits underlying the day’s most popular technologies. We know this field is advancing rapidly and we want to bring you a regular resource to keep you informed and state-of-the-art. The news bites are constantly being added in reverse date order (most recent on top). With our bulletin board you can check back often to see what’s happening in our rapidly accelerating industry. Click HERE to check out previous “AI News Briefs” round-ups.

[1/23/2024] According to Toby Coulthard, CPO at Phrasee, the GPT store bridges the gap in the ChatGPT product adoption curve:
Likelihood of widespread adoption
There’s been interesting discourse in the AI ‘hypefluencer’ space (namely on X) that paints GPTs as glorified instruction prompts and provide no more capability or functionality than before, and therefore provide no utility. They’re missing the point; this is a user experience change, not a capability one. A large part of what OpenAI has been struggling with is that most people beyond the early adopters of ChatGPT don’t know what to do with it. There’s nothing scarier than a flashing cursor in a blank field. ChatGPTs ‘chasm’ in the product adoption curve is that these early majority users want to use ChatGPT but don’t know how. No one was sharing prompts before, now they’re sharing GPTs, and the GPT Store facilitates that. The GPT Store opens the door to the next 100m+ weekly active users.
Prospects for monetizing
With the recent launch, I expect there to be a few very profitable GPTs, with a very large, long-tail of GPTs that are free to use. Plugins will allow for further monetization through third-party services via APIs, but that’s further down the line.
Challenges and Competition
The comparison with an ‘app store’ is misguided, OpenAI isn’t facilitating the dissemination of applications, they’re facilitating the dissemination of workflows. Principally from the most advanced ChatGPT users with experience in prompt engineering, to the least. It’s improving the usability and accessibility of ChatGPT, and its intention is increased adoption and improved retention – in that regard it will improve OpenAI’s competitiveness. They also act as ‘agents lite’. OpenAI has even admitted this is a first step towards autonomous agents. They have a reputation of releasing earlier versions to democratize the ideation of use cases – both beneficial and harmful to inform where the product should go. OpenAI is aware that even they don’t know all the use cases for their models – the GPT Store enables them to see what people produce and what’s useful, popular, and potentially dangerous before they build in more capability and autonomy to these GPTs. The challenges lie in the edge-cases that OpenAI is yet to think of.
![]()
[1/23/2024] RagaAI, an AI-focused startup, has successfully closed a $4.7m seed funding round. The round was led by pi Ventures with participation from global investors including Anorak Ventures, TenOneTen Ventures, Arka Ventures, Mana Ventures, and Exfinity Venture Partners.
The sprawl of large language models (LLMs), computer vision and natural language processing (NLP) have created a new generation of applications that are reshaping industries and transforming how we engage with the world today. Ensuring the performance, safety and reliability of AI has become a key focus. Helping companies stay on top of this, RagaAI has launched from stealth with an automated and comprehensive AI testing platform.
[1/22/2024] NEW research paper: “Self-Rewarding Language Models“- this paper discusses Self-Rewarding Language Models (Self-Rewarding LMs) that show exceptional performance by using an LLM-as-a-Judge mechanism during Iterative DPO training, eclipsing models like Claude 2 and GPT-4 0613 AlpacaEval 2.0 evaluator. The paper demonstrates how to employ LLM-as-a-Judge to enable Self-Rewarding LMs to assign and improve rewards autonomously. Iterative DPO for training is used, allowing the model to refine instruction-following and reward-modeling capabilities across iterations. A strategy is utilized to fine-tune Llama 2 70B over three such iterations for enhanced performance.
[1/19/2024] Open Interpreter is an open-source project that allows LLMs run code such as Python, Javascript, Shell, etc. locally. You can chat with Open Interpreter through a ChatGPT-like interface in your terminal by running $interpreter after installing. This tool provides a NL interface to your computer’s general-purpose capabilities. The latest update introduces the “Computer API” which provides programmatic control over system I/O operations, enabling screenshot capturing, text-based mouse click simulations, icon-based mouse movements, and clipboard content access. While it uses GPT-4, it also supports 100 LLMs including Claude and PaLM.
[1/19/2024] CEO Mark Zuckerberg announced that by year end 2024, Meta plans to develop a massive compute infrastructure including 350,000 NVIDIA H100s, with a total expenditure potentially nearing $9 billion. These are in addition to additional GPUs, amounting to nearly 600,000 H100 equivalents of compute power.
[1/18/2024] 100 Best Resources to become a Prompt Engineer – “Prompt engineering” is a specialized field within the domain of AI and NLP. It involves crafting effective prompts or inputs to AI language models, enabling them to generate desired outputs accurately. Many large companies are recruiting so-called “prompt engineers” with salaries in the $300,000 range. This level of compensation is astonishing considering how young this professional field is.
[1/18/2024] Over on the Unconfuse Me podcast, Sam Altman of OpenAI and Microsoft’s Bill Gates recently discussed the future of AI, including the development of ChatGPT and the pursuit of superintelligence. They discussed enhancing ChatGPT with video capabilities and improving its reasoning abilities. The focus is on making the upcoming GPT-5 model more accurate and customizable, with potential access to users’ personal data for a tailored experience. Altman expressed concerns about the technology’s reliability and the need for better control measures, and also stressed his long-term goal is to achieve superintelligence, a level of AI that surpasses human cognitive abilities.
[1/17/2024] NEW research paper: “RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture” – this paper discusses the tradeoff between RAG and fine-tuning when using LLMs like Llama 2 and GPT-4. It performs a detailed analysis and highlights insights when applying the pipelines on a dataset from the agricultural problem domain.
RAG is effective where data is contextually relevant such as interpretation of farm data. However, it might significantly increase the prompt size and become harder to navigate. Fine-tuning, on the other hand, could be tuned for brevity and can incur less cost when dealing with large datasets. The challenge is the initial cost and effort required to fine-tune models on new data. Overall, the suitability of each approach depends on the specific application, the nature and size of the data, and available resources for model development. There is also the possibility of combining the two approaches.
![]()
[1/17/2024] Our friends over at Deci today have released their new DeciCoder-6B & DeciDiffusion 2.0! DeciCoder-6B is a code LLM engineered for cost efficient performance at scale. Gain outstanding accuracy. DeciCoder-6B outperforms CodeGen 2.5 7B & StarCoder 7B on HumanEval, leading in most languages and ahead by 3 points in Python over StarCoderBase 15.5B. Achieve 19x higher throughput compared to other models in the 7-billion parameter class when running DeciCoder-6B on Qualcomm’s Cloud AI 100 solution. Maximize computational resources with DeciCoder-6B’s smaller model footprint and efficient batching capabilities. To start using DeciCoder-6B, check out these useful resources:
DeciDiffusion 2.0 – 2.6x faster & 61% cheaper with on-par image quality! Create images in only a second and 2.6x faster than Stable Diffusion v1.5 with on par image quality. DeciDiffusion 2.0’s enhanced latency results in 61% cost reduction compared to Stable Diffusion v1.5 when running on Qualcomm’s Cloud AI 100 solution. Released under the CreativeML Open RAIL++-M License. To start using DeciDiffusion 2.0, check out these useful resources:
[1/16/2024] The video presentation below features a recent congressional hearing regarding AI-ready workforce. The U.S. is a global leader in AI, with American companies and institutions at the forefront of sophisticated AI models and cutting-edge research. As AI adoption is increasingly widespread globally, maintaining this lead is important for the needs of national security and economic prosperity. The discussion includes concerns about the STEM education pipeline, especially in cybersecurity, pointing to the need for alternative education programs like boot camps for training and upskilling.
![]()
[1/15/2024] OpenChat released a high-performing open-source 7B LLM, surpassing Grok0, ChatGPT (March), and Grok1. OpenChat is a library of open-source language models fine-tuned with C-RLFT or “Conditioned-Reinforcement Learning Fine-Tuning,” which works by categorizing different data sources as separate reward labels. It’s basically a fine-tuning process for language models using mixed-quality data. Instead of treating all training data equally or needing high-quality preference data, C-RLFT assigns a class or condition to each data source, leveraging these as indicators of data quality. The LLM is available on platforms like HuggingFace, GitHub, and through a live demo. Detailed instructions for independent deployment, including setup for an accelerated vLLM backend and API key authentication, are available on GitHub.
![]()
[1/15/2024] Embedchain is an Open Source RAG Framework that makes it easy to create and deploy AI apps. At its core, Embedchain follows the design principle of being “Conventional but Configurable” to serve both software engineers and machine learning engineers. Embedchain streamlines the creation of Retrieval-Augmented Generation (RAG) applications, offering a seamless process for managing various types of unstructured data. It efficiently segments data into manageable chunks, generates relevant embeddings, and stores them in a vector database for optimized retrieval. With a suite of diverse APIs, it enables users to extract contextual information, find precise answers, or engage in interactive chat conversations, all tailored to their own data.
![]()
[1/13/2024] Mixtral is in a position to surpass GPT-4 this year. Currently, it’s the only open-source model at the top in LLM arena (followed by GPT-4, Claude, and Mistral Medium) and the smallest one as a 7B dense transformer. It’s even better than Google’s Gemini Pro! Plus, it’s open-source! You can take the model and deploy it wherever you wish. You can fine-tune it. You can use it however you see fit. This is gold for the ecosystem. You can deploy Mixtral and start using it immediately. You will find the step-by-step instructions and code in this Google Colab. Read the company’s recent research paper “Mixtral of Experts.”
The code uses @monsterapis who recently launched their platform where you can fine-tune and deploy open-source models. You can read their latest updates, get free credits and special offers, by joining their Discord server HERE.
[1/12/2024] NVIDIA GenAI Examples – This GitHub repo provides state-of-the-art, easily deployable GenAI examples optimized for NVIDIA GPUs. It includes GPU-optimized containers, models, and tools, plus NVIDIA’s latest contributions to programming frameworks and deep learning libraries. The repo features examples like the RAG pipeline for multimodal data and optimized NVIDIA LLMs for enterprise applications.
[1/11/2024] NEW research paper: “Direct Preference Optimization: Your Language Model is Secretly a Reward Model” (published at NeurIPS late last year)- this paper proposes a much simpler alternative to RLHF (reinforcement learning from human feedback) for aligning language models to human preferences. Further, people often ask if universities — which don’t have the massive compute resources of big tech — can still do cutting-edge research on large language models (LLMs). The answer is a resounding yes! This paper is a great example of algorithmic and mathematical insight arrived at by an academic group.
RLHF became a key algorithm for LLM training thanks to the InstructGPT paper, which adapted the technique to that purpose. DPO significantly simplifies things. Rather than needing separate transformer networks to represent a reward function and an LLM, the paper demonstrate how you can determine the reward function (plus regularization term) that that LLM is best at maximizing. This reduces the previous two transformer networks into one. Thus, you now need to train only the LLM and no longer have to deal with a separately trained reward function. The DPO algorithm trains the LLM directly in order to make the reward function consistent with the human preferences.
[1/11/2024] OpenAI just opened the GPT Store! This is the game changing Apple App Store moment for ChatGPT. People have already created incredibly useful GPT Agents in the past few weeks. OpenAI is about to create millionaires. OpenAI also announced a new ChatGPT Team Plan, priced at $25/month/user (annual) or $30/month (monthly), offers a shared workspace and user management tools. OpenAI is also planning a new monetization platform for the GPT Store

![]()
[1/10/2024] Perplexity AI, a new kind of search engine, recently raised $73.6 million, offering a valuation of $520 million. The start-up came out of stealth in August 2022 and is already making waves in search. Perplexity AI is different because you can converse with it like a colleague and ask questions. It then provides answers along with citations for the information.
[1/10/2024] Governor Josh Shapiro announced that his state of Pennsylvania has become the first state to implement ChatGPT Enterprise. A collaboration with OpenAI, this pilot program allows state employees using ChatGPT Enterprise to assist in various tasks such as creating and editing copy, updating policy language, drafting job descriptions, and generating code. This initiative aims to leverage the advantages of GenAI while addressing potential risks. Initially, the tool will be used by a select group of government employees, with plans to expand its use across different sectors of the state government. The partnership with OpenAI is expected to provide insights into how AI tools can responsibly improve state services.
[1/10/2024] NEW research paper: “Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4” – this paper introduces 26 guiding principles designed to streamline the process of querying and prompting large language models. The goal is to simplify the underlying concepts of formulating questions for various scales of large language models, examining their abilities, and enhancing user comprehension on the behaviors of different scales of large language models when feeding into different
prompts. Extensive experiments are conducted on LLaMA-1/2 (7B, 13B and 70B), GPT-3.5/4 to verify the effectiveness of the proposed principles on instructions and prompts design. The hope is that this work provides a better guide for researchers working on the prompting of large language models. The GitHub repo for the project is available HERE.
[1/10/2024] Google launching premium Bard Advanced: Newly discovered screenshots and code indicate Google is working on a paid “Bard Advanced” option powered by its top-tier AI model Gemini Ultra, along with new customization features.
[1/9/2024] NVIDIA plans to begin mass production in Q2 2024 of a new AI chip it designed for China to comply with U.S. export regulations.
[1/9//2024] The following community paper read presentation is sponsored by our friends over at Arize. The paper is “How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings,” by co-author Shuaichen Chang, now an Applied Scientist at AWS AI Lab. Shuaichen’s research (conducted at the Ohio State University) investigates the impact of prompt constructions on the performance of large language models (LLMs) in the text-to-SQL task, particularly focusing on zero-shot, single-domain, and cross-domain settings. Shuaichen and his co-author explore various strategies for prompt construction, evaluating the influence of database schema, content representation, and prompt length on LLMs’ effectiveness. The findings emphasize the importance of careful consideration in constructing prompts, highlighting the crucial role of table relationships and content, the effectiveness of in-domain demonstration examples, and the significance of prompt length in cross-domain scenarios.
[1/9/2024] Benchmarking OpenAI – How do GPT models perform on classifying hallucinated and relevant responses? Our friends over at Arize have put together a compelling blog article that provides a good start for teams looking to better understand how GPT models and OpenAI features perform on correctly classifying hallucinated and relevant responses and the trade-offs between speed and performance for different LLM application systems. As always, the generative AI and LLMOps space are evolving rapidly so it will be interesting to watch how these findings and the space change over time.
[1/9/2024] Copilot for physicians by Paris-based startup Nabla, specializing in AI technology for healthcare. Nabla’s AI copilot assists physicians by taking notes and writing medical reports during patient consultations using speech-to-text technology and a LLM for processing. Founded by Alexandre Lebrun, Delphine Groll, and Martin Raison, Nabla aims to support physicians without replacing them, focusing on administrative efficiency while keeping physicians in control. Nabla combines Microsoft Azure’s speech-to-text API with its model, fine tuning with real-world data from millions of consultations.

[1/8/2024] OpenAI, perhaps the most recognizable name in the artificial intelligence game, sheds more light on its ongoing initiative to transform the landscape of Generative Pre-trained Transformers (GPTs): the OpenAI ChatGPT Store. The announcement details how and why it benefits creators and builders alike, by providing a storefront to share their GPTs and be compensated for their efforts, opening up new revenue possibilities that ceased to exist previously.
For additional context, the GPT Store will become a dynamic marketplace where creators can build and monetize their GPTs. GPTs may range from virtual assistance to coding help, creative writing, fitness coaching, and more diverse AI models that exist to offer a range of services. The platform allows for buying, selling, or accessing AI models tailored for both specific tasks and industries.
Key takeaways
- Searchability and Recognition: GPTs featured in the store will be easily searchable, empowering users to find models that align with their specific needs. The store incorporates a leaderboard feature to provide a ranking of GPTs based on popularity or effectiveness.
- Monetization and Popularity: In addition to showcasing useful GPTs, the store offers creators the opportunity to make money off their models. This feature is especially beneficial for independent developers and small companies trying to break into the AI space.
- Democratizing AI: The GPT Store marks a significant stride in democratizing AI. It will serve as a one-stop shop for creators to monetize their innovations and for users to access a vast array of AI-powered applications.
Chelsea Alves, a Consultant at UNmiss shares, “This initiative not only propels the ever-growing field of artificial intelligence forward but also empowers creators to turn their hard work into a rewarding effort. The democratization of AI through the OpenAI ChatGPT Store becomes more beneficial for creators to be recognized and fairly financially compensated for their contributions. A sticking point with AI-content generation has long been its use of existing content as well as how that derails the authenticity and hard work put in by the original content creator. The OpenAI ChatGPT Store addresses this concern by creating a platform where creators are not only acknowledged for their efforts but also benefit through financial means. This innovative marketplace facilitates a fairer compensation model that will likely, in turn, prompt creators to get even more creative to reap the advantages.”
The OpenAI ChatGPT Store is scheduled to open sometime this week. To get started using the store, will vary depending on the complexity. In a Reddit discussion, one user states, “From the basic end if you can articulate well and upload knowledge files, you can get one going in a short time. If you want to connect with outside APIs there is a bit more you will need to know, but there resources are out there to learn about this.”
[1/6/2024] Microsoft unveiled its first major keyboard redesign in 30 years. Starting in January, some new PCs that run the Windows 11 OS will include a special “Copilot key” that launches Microsoft’s AI chatbot. Getting 3rd party PC makers to add an AI button to laptops is the latest move by the company to capitalize on its partnership with OpenAI. Microsoft has not yet indicated which PC makers are installing the Copilot button beyond the company’s own Surface devices. Some companies are expected to announce new models at CES next week.
[1/5/2024] OpenAI’s GPT Store launching next week: OpenAI plans to launch its GPT Store next week, after a delay from its initial November announcement majorly due to upheaval in the company including CEO Sam Altman’s temporary departure. This platform is strategically positioned as more than just a marketplace, but rather a significant pivot for OpenAI, shifting from a model provider to a platform enabler.
The GPT Store will allow users to share and monetize custom GPT models developed using OpenAI’s advanced GPT-4 framework. This move is significant in making AI more accessible. Integral to this initiative, the GPT Builder tool allows the creation of AI agents for various tasks, removing the need for advanced programming skills. Along side the GPT Store, OpenAI plans to implement a revenue-sharing model based on the usage of these AI tools. Additionally, a leaderboard will feature the most popular GPTs, and exceptional models will be highlighted in different categories.
[1/4/2024] OctoAI announced the private preview of fine-tuned LLMs on the OctoAI Text Gen Solution. Early access customers can:
- Bring any fine-tuned Llama 2, Code Llama, or Mi(s/x)tral models to OctoAI, and
- Run them at the same low per-token pricing and latency as the built-in Chat and Instruct models already available in the solution.
The company heard from customers that fine-tuned LLMs are the best way to create customized experiences in their applications, and that using the right fine-tuned LLMs for a use case can outperform larger alternatives in quality and cost — as the figure below from OpenPipe shows. Many also use fine-tuned versions of smaller LLMs to reduce their spending and dependence on OpenAI. But popular LLM serving platforms charge a “fine-tuning tax,” a premium of 2x or more for inference APIs against fine-tuned models
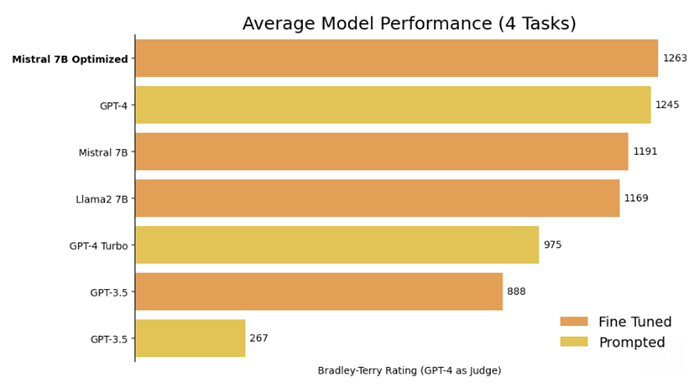
OctoAI delivers good unit economics for generative AI models, and these efficiencies extend to fine-tuned LLMs on OctoAI. Building on these, OctoAI offers one simple per-token price for inferences against a model – whether it’s the built-in option or your choice of fine-tuned LLM.
![]()
[1/3/2024] Intel Corp. (Nasdaq: INTC) and DigitalBridge Group, Inc. (NYSE: DBRG), a global investment firm, today announced the formation of Articul8 AI, Inc., an independent company offering enterprise customers a full-stack, vertically-optimized and secure generative artificial intelligence (GenAI) software platform. The platform delivers AI capabilities that keep customer data, training and inference within the enterprise security perimeter. The platform also provides customers the choice of cloud, on-prem or hybrid deployment.
Articul8 offers a turnkey GenAI software platform that delivers speed, security and cost-efficiency to help large enterprise customers operationalize and scale AI. The platform was launched and optimized on Intel hardware architectures, including Intel® Xeon® Scalable processors and Intel® Gaudi® accelerators, but will support a range of hybrid infrastructure alternatives.
“With its deep AI and HPC domain knowledge and enterprise-grade GenAI deployments, Articul8 is well positioned to deliver tangible business outcomes for Intel and our broader ecosystem of customers and partners. As Intel accelerates AI everywhere, we look forward to our continued collaboration with Articul8,” said Pat Gelsinger, Intel CEO.
[1/2/2024] GitHub repo highlight: “Large Language Model Course” – an comprehensive LLM course on GitHub paves the way for expertise in LLM technology.
[1/2/2024] Sam Altman and Jony Ive recruit iPhone design chief to build new AI device. Legendary designer Jony Ive, known for his iconic work at Apple, and Sam Altman are collaborating on a new artificial intelligence hardware project, enlisting former Apple executive Tang Tan to work at Ive’s design firm, LoveFrom.
[1/2/2024] Chegg Experiencing “Death by LLM”!?! Chegg began in 2005 as a disruptor, bringing online learning tools to students and transforming the landscape of education. But since the company stock’s (NYSE: CHGG) peak in 2021, Chegg has taken a significant nose dive of more than 90% while facing competition with the widely accessible LLMs, e.g. ChatGPT that came out on November 30, 2022. In August 2023, Chegg announced a partnership with Scale AI to transform their data into a dynamic learning experience for students after already collaborating with OpenAI on Cheggmate. A recent Harvard Business Review outtake highlights the potential value that Chegg’s specialized AI learning assistants may bring to a student’s learning experience by using feedback loops; instituting continuous model improvement; and training the model on proprietary datasets. The question remains however, can Chegg effectively associate their user data with AI to reclaim lost competitive ground and take advantage of new revenue streams, or is it fighting a losing battle against the rapidly evolving GenAI ecosystem? Personally, I have no love lost with Chegg, as I’ve discovered a number of of my Intro to Data Science students cheating on homework assignments and exams by accessing my coursework uploaded to Chegg.
[1/2/2024] AI research paper highlight: “Gemini: A Family of Highly Capable Multimodal Models,” the paper behind the new Google Gemini model release. The main problem addressed by Gemini is the challenge of creating models that can effectively understand and process multiple modalities (text, image, audio, and video) while also delivering advanced reasoning and understanding in each individual domain.
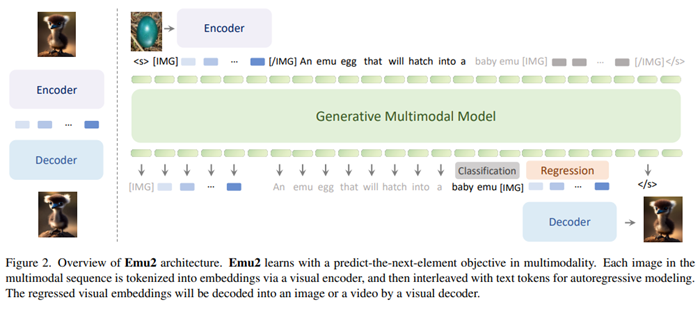
[1/2/2024] AI research paper highlight: “Generative Multimodal Models are In-Context Learners.” This research demonstrates that large multimodal models can enhance their task-agnostic in-context learning capabilities through effective scaling-up. The primary problem addressed is the struggle of multimodal systems to mimic the human ability to easily solve multimodal tasks in context – with only a few demonstrations or simple instructions. Emu2 is proposed, a new 37B generative multimodal model, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 consists of a visual encoder/decoder, and a multimodal transformer. Images are tokenized with the visual encoder to a continuous embedding space, interleaved with text tokens for autoregressive modeling. Emu2 is initially pretrained only on the captioning task with both image-text and video-text paired datasets. Emu2’s visual decoder is initialized from SDXL-base, and can be considered a visual detokenizer through a diffusion model. VAE is kept static while the weights of a diffusion U-Net are updated. Emu-chat is derived from Emu by fine-tuning the model with conversational data, and Emu-gen is fine-tuned with complex compositional generation tasks. Results of the research suggests that Emu2 achieves state-of-the-art few-shot performance on multiple visual question-answering datasets and demonstrates a performance improvement with an increase in the number of examples in context. Emu2 also learns to follow visual prompting in context, showcasing strong multimodal reasoning capabilities for tasks in the wild. When instruction-tuned to follow specific instructions, Emu2 further achieves new benchmarks on challenging tasks such as question answering for large multimodal models and open-ended subject-driven generation.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideBIGDATANOW
